1. The question has moved
The live question in applied AI is no longer whether more thinking helps — it is how much thinking each problem deserves. Compute has become the binding constraint of the field: every deployed system now sits behind a budget, and the budget is always smaller than the demand. The test-time-compute literature has made real progress on this inside a single reasoning trace: adaptive decoding, budgeted search, learned stopping rules (Snell et al., 2024, is a good entry point). All of that work shares a unit of analysis: one problem, one trace, one budget.
The more consequential decision sits one level up. A deployed system faces many kinds of task — dozens of categories, arriving continually — and a budget that covers only a fraction of them. Before any within-trace cleverness can matter, something must decide which categories get a trace at all. That decision is not reasoning; it is the executive function above reasoning, and it can be defined and measured like any other faculty:
(F1) executive layer: (budget B, competence map M) -> allocation a graded by: value_captured / compute_spent, vs allocation baselines — reads as: the executive layer maps a finite budget and a memory of past performance to a spending plan over task categories; it is judged by value per unit compute against competing allocation policies, held out.
This layer is not unoccupied territory. Damani et al. (2025) allocate a fixed budget across queries using predictors trained on past outcomes; deployed model routers are competence maps in production (Ong et al., 2024); batch-level allocation is an active 2025–26 thread. What the existing work has not done — and what this essay contributes — is the controlled comparison at that layer: (i) twelve allocation policies spanning the full exploration–exploitation continuum, plus the progress-seeking axis, head-to-head on one real portfolio under one budget; (ii) the dose-response result — value falls monotonically with exploration weight, and even the field's repaired curiosity trails pure exploitation; (iii) the audit machinery — permutation null, jackknife, temporal splits — that lets a result like this be trusted; and (iv) measured boundary conditions: where the advantage comes from, when it inverts, and why there is no cold-start crossover. The claim I defend is deliberately narrow: during exploitation — after substantial historical experience — a memory of your own past competence allocates a fixed budget better than uniform, better than curiosity in both its naive and repaired forms, and better than standard bandit algorithms. Two of the experiments limit the claim, and they are reported with the same prominence as the ones that support it.
The question is not how long to think about a problem — it is which problems deserve your thinking at all.
2. Ways to spend a budget
The testbed is a forecasting system I build and operate. It makes out-of-sample predictions about real historical processes across roughly 55 task categories in three families: competitive-match outcomes, seasonal physical processes, and macroeconomic series. Every prediction is graded against reality and against a per-category baseline. The record of those grades — roughly 88,000 resolved out-of-sample predictions, summarised per family — is what I will call the system's competence map: its memory of where effort has historically converted to value. The experimental question: given a budget large enough to probe only a quarter of a held-out task pool, which categories should get it?
(F2) maximise sum_i a_i * E[ value_i | competence_i ] subject to sum_i a_i <= B — reads as: spend where remembered competence times downstream value per unit cost is highest; a_i is compute given to category i, B is the total budget.
The policies compete as scoring functions over categories:
(F3) uniform: score_i = constant curiosity: score_i = uncertainty_i (naive: explore where least sure) learning-progress: score_i = d(skill)/d(effort) for family(i) competence: score_i = E[ value_i | past track record on i ] bandits: score_i = competence_i + k * exploration_bonus_i — reads as: allocate the budget greedily by score. Uniform ignores history; naive curiosity seeks what it knows least; learning progress seeks where it is improving; competence reads the map; UCB and Thompson Sampling sit between competence and curiosity.
Two design details matter for honesty. First, the competence map is learned only from the training half of each split — the policy never sees the outcomes it is graded on. Second, raw task identity is useless as a competence feature, because each category appears once; the map must be drawn at the level of repeating families, or there is nothing to generalise from. This is not a stylistic choice: an ablation in section 6 shows that memory at the family level delivers the entire advantage (+25%), while global or per-category memory delivers essentially none (~+2%). The granularity is the mechanism. The metric, throughout, is value captured per unit of compute, reported as a lift over the competing policy — never as a raw internal score.
3. The result: competence > uniform > naive curiosity
Over 200 random train/test splits, at a budget of one quarter of the held-out pool: the competence allocator captured 1.22× the value per unit compute of the uniform policy (bootstrap 95% CI [+19%, +26%], Cohen's d = 0.99) and 1.67× that of the naive curiosity policy (CI [+63%, +74%], d = 2.25). Naive curiosity did not merely lose to the self-model — it lost to blind uniform allocation, capturing 0.73× the value of spreading the budget evenly.
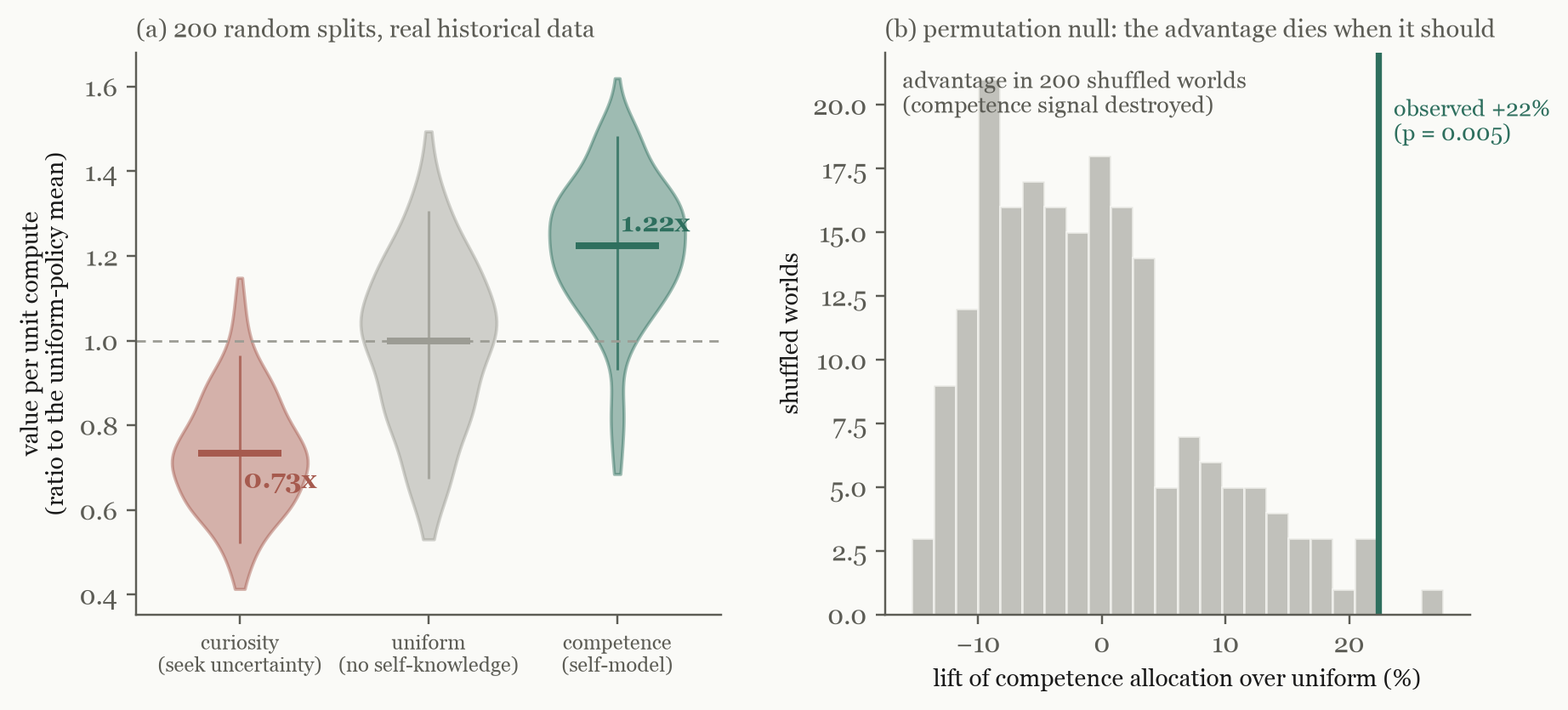
Because a mean over splits can hide seed luck, the distribution matters more than the point estimate. The competence-over-curiosity gap is positive in 97.5% of the 200 splits and its 5th percentile is still positive — the gap essentially never closes. The competence-over-uniform gap is positive in 82% of splits and does cross zero in the tail. So I treat beating curiosity as the primary claim and beating uniform as the supporting one — and section 5 will qualify the supporting claim further, because a jackknife shows where it comes from.
One result I did not expect: a fuller self-model — competence plus task features like data volume and baseline difficulty — performed about 2% worse than competence alone. Adding features diluted the introspective signal rather than sharpening it. I report this because it is the kind of detail that would be easy to leave out, and because it sharpens the finding: the value is in the self-knowledge, not in a bigger regression.
Chasing uncertainty was not just suboptimal. It was worse than allocating blindly.
4. The stronger opponents: bandits, and the exploration continuum
An expert reader's first objection should be: allocation from a noisy per-category reward history is a bandit problem — where are UCB and Thompson Sampling (Thompson, 1933; Auer et al., 2002; Lattimore & Szepesvári, 2020)? They are in the harness, and they make the finding cleaner, not weaker. In this one-shot-budget setting a bandit reduces to a scoring function: remembered competence plus an exploration bonus. That makes the uncertainty-driven policies points on a single continuum, from pure exploitation to pure exploration:
(F4) score_i(beta) = (1-beta) * z(competence_i) + beta * z(uncertainty_i) UCB: score_i = competence_i + k * spread * sqrt( 2 ln N / n_family(i) ) — reads as: beta = 0 is the pure competence policy, beta = 1 is pure curiosity; UCB and Thompson are principled intermediate points whose bonus shrinks as a family accumulates history.
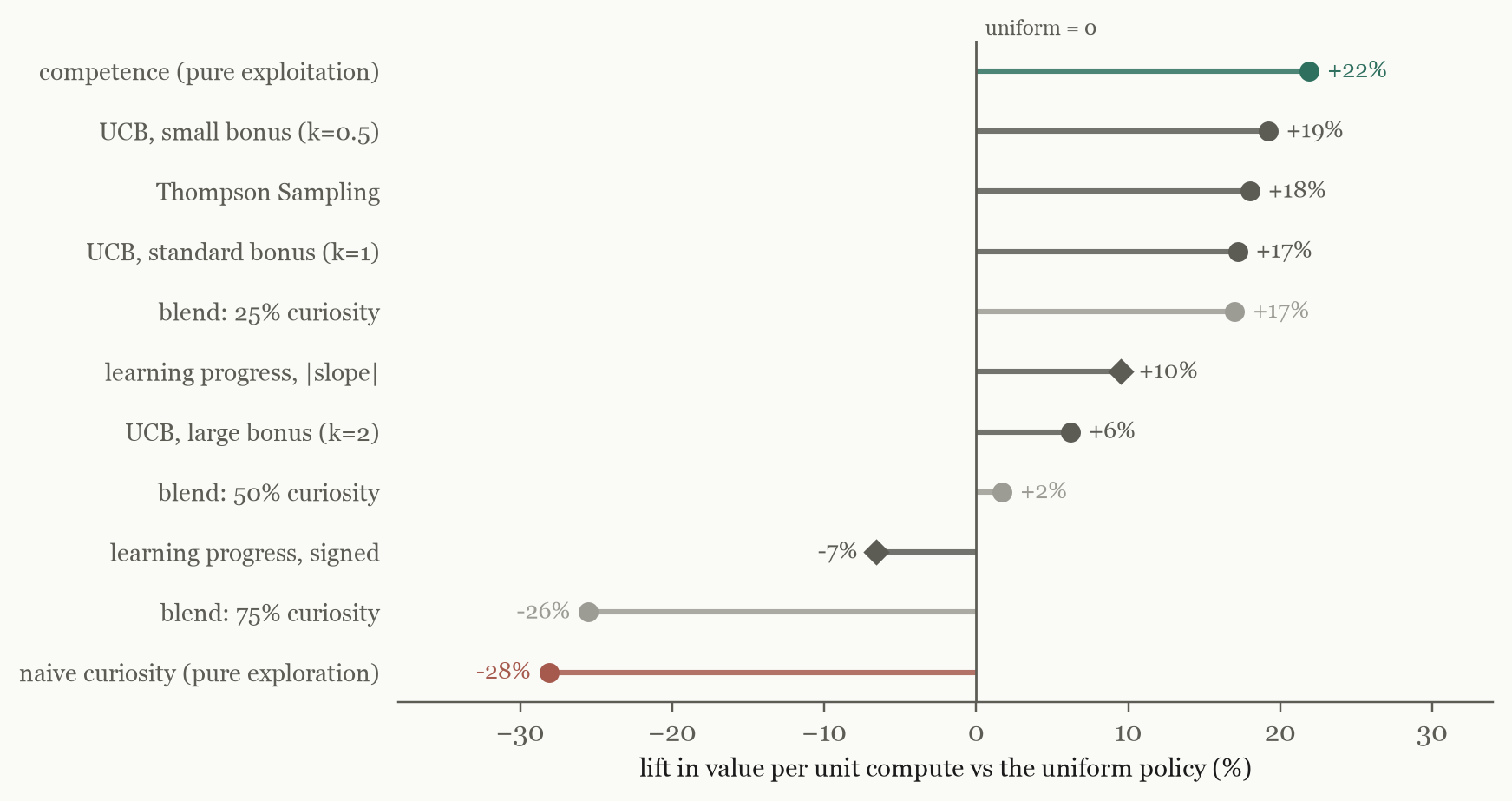
The ordering along the exploration axis is strict: competence-only beats small-bonus UCB, which beats Thompson Sampling and standard UCB, which beat larger bonuses and every explicit blend, all the way down to pure curiosity. The margins between competence and the best bandits are modest (2–3%) — but the monotone trend is the point: in a portfolio with a stable competence structure and a substantial track record, the optimum sits at the pure-exploitation end of the continuum. This is not an anomaly of my harness: the bandit literature itself has documented greedy's strength once enough arms or context exist — pure greedy empirically beats UCB and Thompson Sampling in the many-armed regime (Bayati et al., 2020), and exploration-free algorithms are rate-optimal under covariate diversity (Bastani et al., 2021). The continuum result replicates that theory-backed phenomenon in a new setting — a one-shot portfolio with the competence map generalised over a family structure — and extends it with the dose-response shape. Exploration bonuses are insurance against a world that might change; here the premium bought nothing. (I did not test EXP3-style adversarial bandits: they are designed for rewards chosen by an adversary, and nothing here is adversarial — the uncertainty is nature's.)
It is worth saying precisely why this is not simply a bandit paper. Bandit algorithms answer a sequential question — how to trade regret against learning across repeated pulls — and their statistics live per arm. The question here is one-shot and introspective: given a map already paid for, how should a single budget be split — and the load-bearing feature is not an arm statistic but the system's own realized skill, generalised across a family structure the arms share. Classical metareasoning (Russell & Wefald, 1991) asks how much computation a single decision is worth; algorithm selection (Rice, 1976) asks which solver fits one problem instance. This sits above both: which problems, of many, deserve computation at all. The continuum result connects the three: when the map is trustworthy, the metareasoning answer collapses to reading it.
Every unit of exploration bonus subtracted value. The optimum sat at the pure-exploitation end.
5. Repairing curiosity — and why the map still wins
Naive uncertainty-seeking fails here for a reason worth stating precisely, because it is not a strawman I invented — it is the original form of a celebrated design principle (Oudeyer & Kaplan, 2007; Pathak et al., 2017; Schmidhuber, 1990, 2010): allocate effort where uncertainty is highest, because that is where there is most to learn.
(F5) useful_curiosity ~ d(error) / d(effort) — reads as: uncertainty is only worth chasing where it is REDUCIBLE — where effort actually shrinks the error. On irreducible noise, curiosity spends and learns nothing.
The failure is concrete in my data. One family — macroeconomic series — is a zone where the system's out-of-sample skill is reliably near zero: the strongest baselines already absorb what is predictable, and what remains is, for this system at this horizon, irreducible. Naive curiosity cannot distinguish "uncertain because unexplored" from "uncertain because unlearnable". It sees maximal uncertainty in exactly the family with minimal returns and pours budget into it.
An intrinsic-motivation researcher will object — correctly — that the field diagnosed this disease long ago and retired the naive policy for it. Chasing raw uncertainty fixates on unlearnable noise: the "noisy-TV problem" (Burda et al., 2018; Mavor-Parker et al., 2022). The accepted repair, from Oudeyer & Kaplan (2007) through R-IAC (Baranes & Oudeyer, 2009) to modern curriculum methods (Portelas et al., 2019), is to chase learning progress — the derivative in F5 — rather than uncertainty itself. F5 is not my critique of curiosity; it is the field's own fix. So the strong comparator is not naive curiosity but a learning-progress allocator, and I ran it: a tenth policy scoring each family by the slope of realized skill over successive probes, estimated from the training half only.
The repair works — against its own disease. Learning progress correctly ignores the failure zone (flat zero skill yields zero progress) and beats naive curiosity by roughly 30%. But it still does not beat the map: the canonical absolute-progress variant captures +10% over uniform — below every bandit tested — the signed variant loses to uniform outright (−7%), and head-to-head the competence map beats learning progress by +30%, winning 75% of splits. The mechanism is this essay's distinction in one line: learning progress allocates to where skill is changing; value capture needs allocation to where skill is high. In a mature portfolio the most valuable families are high and flat — precisely where a progress signal goes quiet. Learning progress is the right teacher and the wrong treasurer: the signal for building the map, not for cashing it.
A leave-one-family-out jackknife then reveals something I had not fully appreciated about my own result — the advantage is not a constant of the method but a function of the portfolio's competence contrast:
| pool variant | vs uniform | vs naive curiosity |
|---|---|---|
| full pool (three families) | +22% | +67% |
| without the failure-zone family | +4% | +20% |
| without the strongest family | +51% | +167% |
| without the seasonal family | +31% | +92% |
Remove the macroeconomic failure zone from the pool entirely, and the advantage over uniform collapses to +4% — most of the gain over blind allocation is the self-model steering around the one family it knows it fails at. The advantage over curiosity, by contrast, survives every jackknife cell. Two readings follow, and both belong in the open: the vs-uniform lift is a function of how much competence contrast your portfolio contains — and a portfolio without failure zones has little for a self-model to know. Real portfolios have failure zones. Knowing yours is the point.
Learning progress is the right teacher and the wrong treasurer.
6. Trying to kill it: controls, a broken control, and time
A result like this is cheap to fake by accident, so most of the work went into attacking it. In total the headline ratios sit on well over one hundred thousand individual policy evaluations: twelve policies × 200 splits on the primary protocol, nine seed-and-budget protocol cells, leave-one-family-out reruns, temporal splits, granularity ablations, two structural controls, and a 200-world permutation test.
The control that worked. On a pool with no competence structure — every category equally learnable — all policies collapse to identical value per unit compute; the lift is exactly 0.0%.
(F6) if competence signal is destroyed (shuffled / absent) then lift -> 0 (or the harness is leaking) — reads as: the honesty gate: the advantage must vanish when there is genuinely nothing to know about yourself.
The control that broke — and what it taught. My first destroyed-signal control shuffled each category's track record once and re-ran the comparison. The advantage refused to die: +12% survived. For an uncomfortable hour this looked like the whole result was a harness artifact. It wasn't — the control was broken: a single fixed shuffle creates chance family structure that is genuinely learnable inside that shuffled world, so a competent allocator legitimately profits from it. The correct test is a full permutation null: re-run the entire experiment in 200 independently shuffled worlds. The null centres on zero (mean −1%); exactly one of 200 shuffled worlds exceeded the observed lift over uniform (p = 0.005), and none reached the observed lift over curiosity — the null's most extreme world managed +47% (p < 0.005).
Our first negative control refused to die. That impeached the control, not the result.
Time as the adversary. Random splits quietly assume competence is stationary, so I also ran the split the hard way: train the map only on the categories probed earliest, allocate over those that arrived later. The advantage holds through half the history — +25%, +28%, +38% over uniform with the earliest 30/40/50% as training — then weakens (+9% at 60%), and at the most extreme cut it inverts (−28%): the latest-arriving pool is dominated by families the system was never good at, only three categories from its strongest family remain, and a map drawn from the past misallocates against that future. (Naive curiosity, for completeness, captured zero value there.) Non-stationary bandit theory predicts exactly this — exploitation is the first casualty of drift (Garivier & Moulines, 2008); the contribution here is a measured boundary on real data. The missing mechanism has a name — competence decay: the map needs to discount its own entries as they age, and to widen its uncertainty when the portfolio's composition drifts. Building and testing that staleness model is the clearest next experiment this result demands.
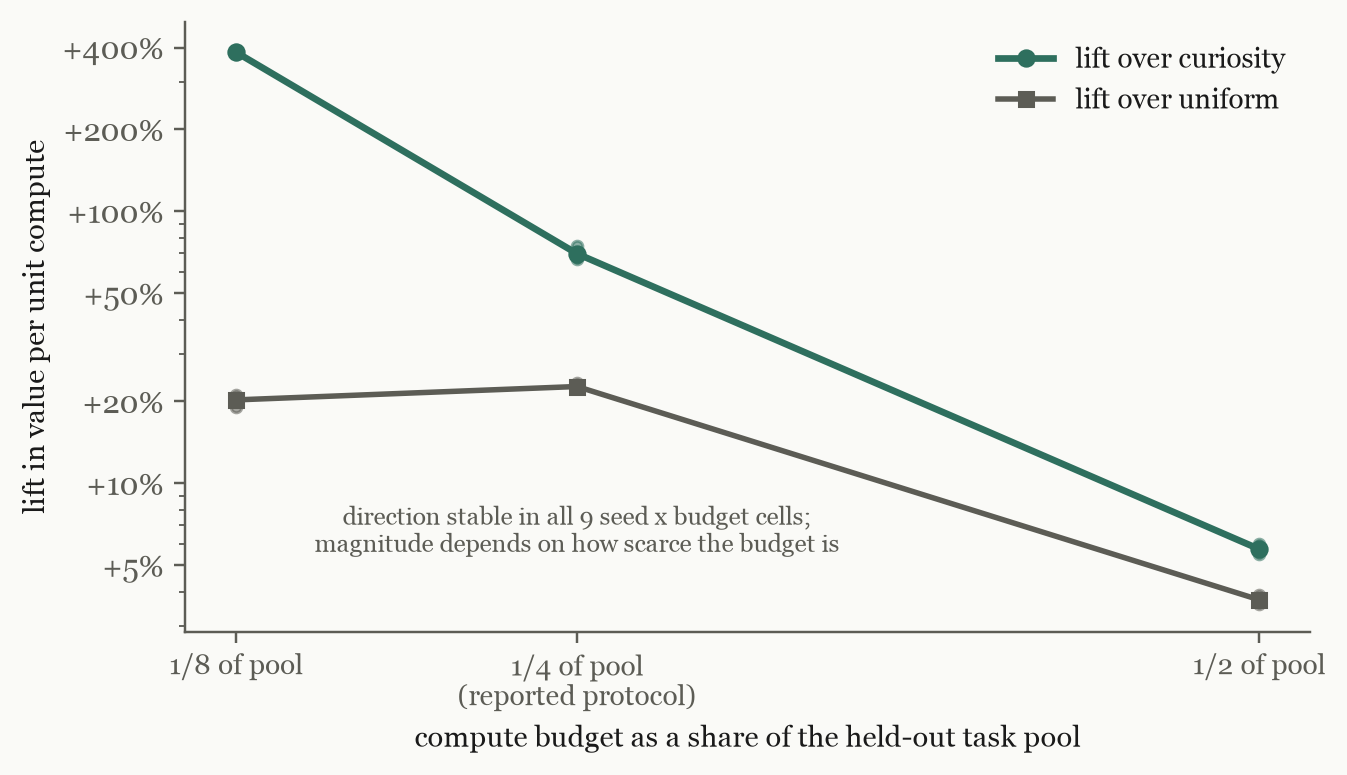
Protocol sensitivity, disclosed. The magnitudes are specific to the reported budget of one quarter of the pool. Sweeping it: with a scarcer budget (one eighth) the advantage over curiosity explodes to roughly 5×; with an abundant one (one half) all policies converge and lifts compress to single digits. Across all nine seed-and-budget cells the sign never flips.
Replication. The experiment was first run when the pool held 41 categories. By the time of the final audit the pool had grown 34%, to 55, through ordinary operation — new data, untouched protocol. The headline lifts moved by less than one percentage point.
7. Complicating a principle I endorse in public
This result is awkward for me, which is partly why I trust it. My own research page, today, says: "Curiosity as compression progress: agents that generate their own curricula and allocate compute to their frontier" — and cites Schmidhuber's world-models-and-artificial-curiosity programme as a foundation. I wrote that, I still believe a version of it, and the measurements above say that as a compute-allocation policy over a task portfolio, the naive reading of it is the worst option I tested — and even the field's repaired reading, learning progress, trails the track record during exploitation.
The reconciliation is that curiosity and competence answer different questions. Curiosity — in both forms — is a learning signal: where might my model of the world improve? Competence is an earning signal: where does my effort convert to value? The intrinsic-motivation literature was built for agents whose job is to grow; a deployed system's budget question is about converting finite compute into results. When a genuine competence structure exists and is reasonably stationary, the earning question is answered better by your own track record than by your own confusion — by a measured factor of 1.67 in this setting, and by a strict monotone ordering across every exploration weight I tried.
Curiosity is a learning signal. A budget is an earning problem.
8. Cold start, and what the self-model still can't do
Theory says exploitation-first allocation should fail at the cold start: a competence map needs a track record, so curiosity must win early, while the map is still blank. That is what I believed when I designed the experiment, and it is what the intrinsic-motivation literature would predict. The measurement disagrees. I expected a crossover; I went looking for it; it never appears.
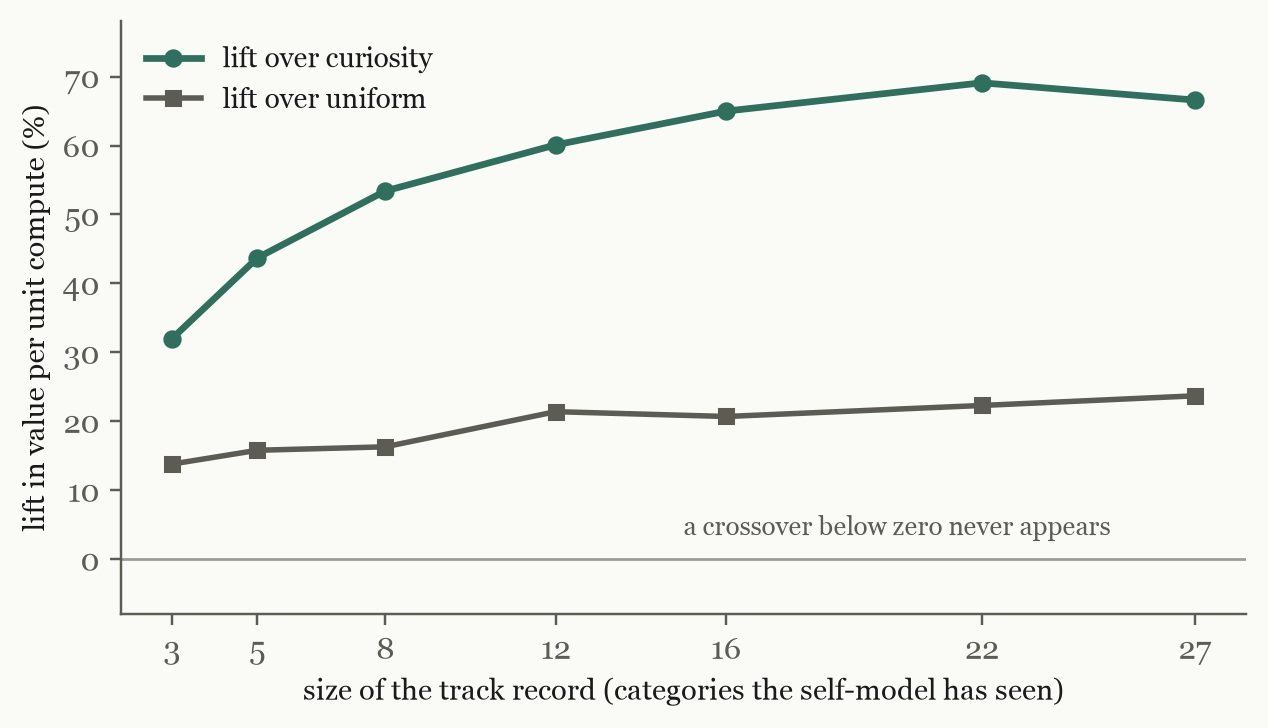
A track record of just three categories — barely one observation per family — already allocates +14% better than uniform and +32% better than naive curiosity; the advantage climbs steadily as the record fills out. Knowing a little about yourself already beats knowing nothing. The honest gloss: in my setting the competence structure is coarse (three families, one of them a failure zone), so a few observations carry most of the signal. In a portfolio with hundreds of fine-grained families, the curve would start lower and the map-building phase would matter more. Curiosity's legitimate role survives in exactly that phase — and the right signal for it is the one the curriculum-learning literature already uses, learning progress (Portelas et al., 2019): not the allocation policy, but the mechanism that builds the map the allocator will exploit.
What the competence map still can't do, from the section-6 results: survive a hard composition shift, price the staleness of its own entries, or construct its own family structure — here the families were natural, and the granularity ablation shows the whole advantage lives at that level. Adaptive competence decay, automatic family discovery, and replication on an unrelated system are the next experiments, not footnotes.
What this is / what this isn't
This is: a held-out comparison of twelve allocation policies — uniform, naive curiosity, UCB (three bonus levels), Thompson Sampling, three curiosity blends, two learning-progress variants, and a competence map — over a portfolio of ~55 real forecasting categories, with an ablation, a granularity ablation, a leave-one-family-out jackknife, temporal splits, a structural control, a 200-world permutation null, a nine-cell protocol sweep, bootstrap confidence intervals, and one changed-data replication.
This isn't: a claim that curiosity is useless (in its learning-progress form it builds the very map competence allocation needs); a claim that bandits are bad algorithms (their bonus buys insurance this stationary setting never cashed); a within-trace compute-control method (they compose); a deployed production controller (the ordering is proven, the wiring is not); or a benchmark result of any kind.
Limitations
The portfolio is ~55 categories in three families, from one proprietary system's history; the effective sample size is the category count and the 200-split resampling, not the ~88,000 underlying predictions those categories summarise. The value metric is internal (out-of-sample skill against per-category baselines), so only ratios are reported. The vs-uniform advantage is mostly failure-zone avoidance: remove the failure-zone family and it drops to +4%, so portfolios without competence contrast should expect little. The advantage inverts under hard composition shift, and the map has no staleness model yet. The learning-progress comparator was tested and reported — it trails the map by 30% head-to-head — but its more sophisticated cousins, such as aleatoric-aware bonuses (Mavor-Parker et al., 2022) or progress estimated within categories rather than across them, were not, and remain open. Magnitudes are budget-dependent in a disclosed, mechanically sensible way. Beating naive curiosity is the strong claim (97.5% of splits, p < 0.005, d = 2.25); beating uniform is real but softer (82% of splits, p = 0.005, d = 0.99); beating the best bandit is consistent but modest. External replication beyond this system does not yet exist and is the single most important piece of future work; the harness's policy implementations will be released in the series' companion repository (github.com/MC-MatthewChilds/honest-measurement) with a synthetic portfolio demonstrator, so the comparison can be rerun on any portfolio with a track record. And the allocator has been demonstrated, not deployed: making the self-model steer the live daily budget is engineering still ahead of me.
Why it matters
Every serious AI deployment is growing an outer loop that decides where compute goes: a mixture-of-experts router choosing which expert fires (Shazeer et al., 2017), an agent framework choosing which sub-task gets a long reasoning trace, a lab's scheduler choosing which experiments to run, an enterprise assistant choosing which requests merit deep work. Today those loops mostly run on uniform shares, hand-set priorities, or uncertainty heuristics — the policies this essay measured, and beat, with bookkeeping. The result suggests the cheapest upgrade available to any system with a track record is an audited memory of its own performance, promoted from dashboard to controller: load-bearing, ablated, permutation-tested, and honest about where it stops working. As budgets tighten and portfolios widen, intelligence will be defined less by how well a system thinks and more by how well it chooses what not to think about. That choice deserves the same rigor we spend on the thinking itself.
Series spine: the honest object is a slope you own and reality grades — not a threshold someone else scores. Article 1 makes that the subject; this piece tries to embody it. All results are held-out, baseline-controlled, and control-audited; distributions are reported rather than point estimates throughout.