The assumption everyone shares
The most influential idea in agent self-improvement right now is also the most intuitive one: store what worked. Voyager (Wang et al., 2023) made it explicit — an embodied agent that writes executable skills, keeps the ones that verify, and draws on an “ever-growing skill library” so that capability compounds without a single parameter update. DreamCoder (Ellis et al., 2021) is the deeper ancestor: alternate between solving problems and compressing the solutions into reusable abstractions, so that yesterday's discoveries make today's search shorter. Stitch (Bowers et al., 2023) and LILO (Grand et al., 2024) carried the compression line forward; the Darwin Gödel Machine (Zhang et al., 2025) applies the same archive logic to whole agents. Across all of them the load-bearing structure is identical: experience becomes stored, verified artifacts, and stored artifacts make future problems cheaper.
We want to be fair to this idea before we complicate it, because in the domains where it was demonstrated it is real. Minecraft's technology tree is deep, and crafting a pickaxe genuinely is a subroutine of mining diamonds. DreamCoder's list-manipulation and graphics domains are rich in shared substructure, so compression has something to bite on. Read through the lens this essay will propose, the canonical successes are depth stories: each of those domains concentrates its solutions well past depth one, with substructure shared across problems — precisely the regime in which banked artifacts have something to compress and somewhere to be reused. The library thesis was not oversold by its authors so much as over-generalised by its readers — us included.
We should say precisely what is and is not new here, because a version of this counter-case has now been reported. In theorem proving, Berlot-Attwell et al. (2024; 2025) examined two prominent LLM-based library learners and found function reuse vanishingly rare — of more than twenty thousand learned lemmas in one system, exactly one was ever reused — with the measured gains tracing to self-correction rather than to the library; and they argue, as we will, that reuse behaviour rather than headline accuracy is the right thing to measure. Those findings are the existing counter-case, for LLM-based learners, in one domain. What this essay adds is the same phenomenon measured in a symbolic system with no LLM anywhere in the loop, in a different domain family; the causal mechanism behind it (the solution-depth histogram of Section 3); and a controlled experiment in which that mechanism is dialled directly (Section 7). Negative results of this kind remain structurally underrepresented — a library that fails to compound rarely makes it into print — so the field's picture of when the mechanism works is still fit largely to its successes. This essay is an attempt to balance that picture with mechanism rather than anecdote.
The neighbouring literatures deserve naming, because each holds a piece of this question. Continual and lifelong learning studies accumulation with parameter updates, where the failure mode is forgetting (Parisi et al., 2019). Episodic-memory and retrieval methods store raw experience and fetch it at inference time (Pritzel et al., 2017; Lewis et al., 2020). Meta-learning moves the compounding into the optimiser itself (Finn et al., 2017). Our subject is narrower than all of these: the non-parametric loop — store verified artifacts, retrieve, compose — and the specific question of how to tell whether it is compounding at all. The measurement discipline below applies to any of these literatures; the counter-case we report is about the library variant.
The library that didn't compound rarely makes it into print — so the field's picture of the mechanism is fit largely to its successes.
What we built, and what we measured
We built the whole loop, on purpose, in the most adversarial domain we work with: solve, verify, bank, reuse — plus a small learned policy on the side, which we initially regarded as plumbing. The domain is a compositional visual-reasoning benchmark: each problem presents a handful of input–output examples of a hidden transformation, and the solver must induce a program that reproduces the transformation exactly on held-out inputs. Exact match; no partial credit. We describe the domain generically throughout and publish ratios rather than raw figures, deliberately: this essay is about a measurement discipline, and we do not want it read as a leaderboard entry.
The solver is a symbolic program-search engine over a domain-specific language of primitive operations and parametric generators. Beside it sits a small learned ranking model — we call it the router — trained on cheap features of a problem to predict which family of moves to try first. It is owned, CPU-trained, and tiny; no large language model appears anywhere in the reasoning loop. That matters here mainly because it keeps the accounting clean: every capability gain below is attributable to a mechanism we can inspect.
The honesty rails were fixed before any measurement. Mining and training happen on a training split only. Every number reported is from held-out problems. A solution passes a leave-one-out gate before anything is banked, and reuse only counts when a banked artifact contributes to a new held-out solve. Proportions are reported with 95% Wilson intervals; ratio uncertainty is bootstrapped; the controlled experiment in the final section reports the spread across ten independent seeds. Every quantitative claim in this essay is out-of-sample, names the baseline it beat, and was checked for leakage.
Then we asked the question the library thesis invites but rarely receives: after a full pass of experience, where did the compounding actually show up?
The library barely compounded — and why
The library stayed nearly empty. After mining our training split, 4.0% of mined problems (95% CI 1.8–8.5%) produced a program that passed the banking gate as reusable multi-step structure. The resulting library was small enough to read in one sitting. Our first hypothesis was a bug in the banking gate. Our second was a broken reuse-detector. The audit found something more interesting: there was almost nothing to bank.
We then measured the cause directly (Figure 1). Of the distinct held-out problems our system has ever solved, 88% were solved by a program of exactly one step — a single primitive, or a single parametric schema instantiated with problem-specific arguments. The remaining 12% took two steps. None took more. A library compounds by compressing shared multi-step structure out of past solutions; if the solutions have almost no multi-step structure, compression has nothing to bite on.
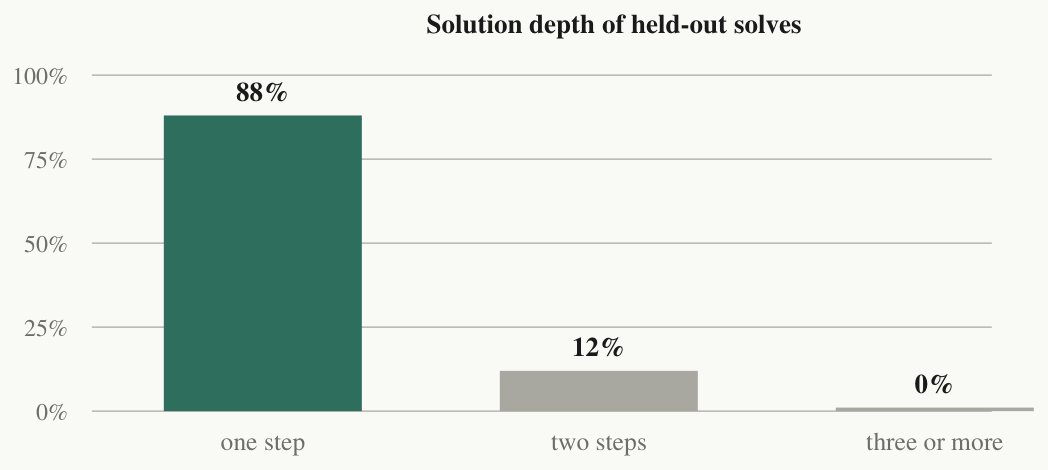
This is worth stating as a general mechanism, because both factors are measurable in any system:
(P1) E[banked per solve] = P(depth >= 2 | solved) x P(passes reuse gate | depth >= 2) — the library's growth rate is bounded by the deep-solution rate before the quality of any banking machinery enters. Here: 0.12 × ~0.4 ≈ 0.05 — the two measured factors multiply out to the observed banking rate.
Note what this is not: it is not “libraries don't work.” It is a domain property, not a learner property. Our domain is explicitly designed to defeat memorisation — each held-out problem is built to require a concept the solver has not seen — which makes it close to a worst case for solution reuse. But that is precisely why the measurement is informative. The field's canonical demonstrations run where solutions are deep and reuse is plentiful, and readers extrapolate the mechanism everywhere else. Ours is the missing data point from the other end of the distribution.
You cannot bank what the domain never produces. The solutions were one step deep, so the shelf stayed empty.
What actually compounded: the router
While the library starved, the policy ate everything, and the asymmetry is structural. A banked program requires a rare event: a multi-step solution that survives a reuse gate. A policy training example requires only a solve of any depth — problem features in, winning move family out. On the same stream of mined experience, 75.3% of it became policy training signal (CI 68–82%), versus 4.0% that became library content (CI 1.8–8.5%): a ~19× difference (CI 10–58×) in how much of its own experience each mechanism can learn from. Even at the conservative edge of the interval, the asymmetry exceeds an order of magnitude.
Since the policy carries the conclusion, it should be described rather than gestured at. The router is a nearest-centroid classifier: two dozen cheap features of a problem (size, symmetry, palette and object statistics of the examples), standardised, compared against one centroid per move family — seventeen families, a few hundred parameters in total. It trains in a fraction of a second on a CPU and retrains from scratch after every mining pass. Nothing about it is clever, and that is the point: if a model this small compounds where the library could not, the explanation is the signal asymmetry, not the architecture. An analogy that survives scrutiny: the library is a warehouse; the policy is the dispatcher. A warehouse only pays for itself when jobs keep needing the same parts. A dispatcher gets better with every job, whatever the parts were.
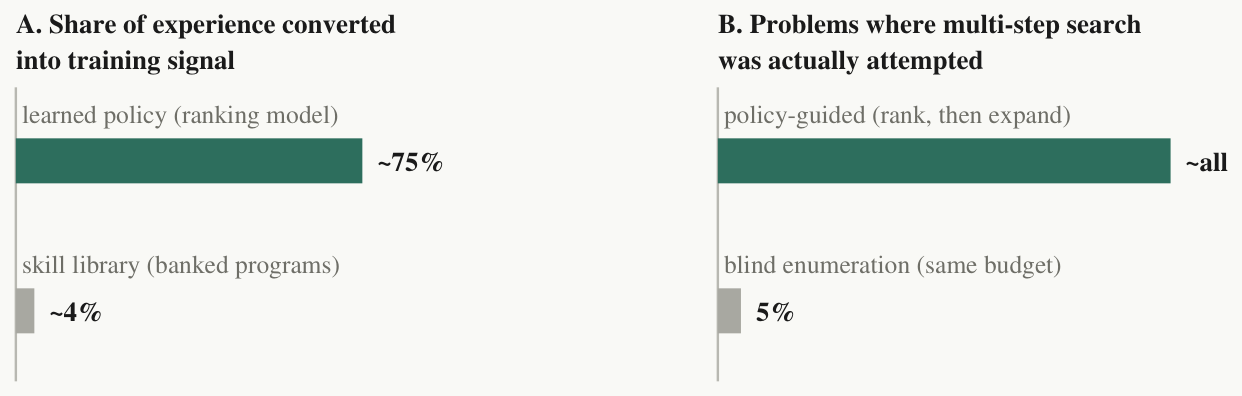
What does the policy buy? Search reach. Under a fixed compute budget, blind multi-step enumeration was being skipped on 95% of problems: the median problem offered roughly 1,800 viable first steps, and expanding all of them before going deeper was hopeless, so the solver never went deeper. We emphasise the verb. Our aggregate metrics initially read as “deep search doesn't help,” and only the logs revealed that deep search was not failing — it was never being tried. With the router's ranking, search becomes rank-then-expand: score the candidate first steps, keep the top handful, expand only those. The same budget now reaches depths blind enumeration never touched.
(F4) guided beam: at each depth, score candidates with policy -> keep top-K -> expand only those — a cheap ranking converts an intractable frontier into a tractable one; the budget is spent on depth instead of breadth.
Learned guidance for search has a distinguished lineage — DeepCoder (Balog et al., 2017) and BUSTLE (Odena et al., 2020) both use a learned model to steer program synthesis toward depths blind enumeration cannot reach — and we claim no novelty for the idea. What we have not seen reported are the two measurements around it: the audit showing that deep search was being silently skipped rather than tried and found wanting, and the ~19× experience-to-signal asymmetry between policy and library on the same stream.
Now the wrinkle, which stays in because this series is built on self-caught errors. The first version of the guided search scored candidate steps by similarity between the current output and the target. That silently assigns a score of zero to any first step that changes the output's shape — an entire class of moves was not down-weighted but structurally invisible. We caught it because one category of problems was never being entered at depth two at all, and fixed it by seeding a canonical set of shape-changing pre-steps ahead of the scorer. The lesson generalises: a learned policy can be confidently, systematically blind, and nothing in your aggregate solve rate will tell you.
Finally, the honest thinness. We retrained the router on growing prefixes of its experience, in mining order, and measured held-out ranking quality (Figure 3). The ranking beats chance ordering from a few dozen examples — a useful property in itself — but the curve then plateaus at our current scale, and the holdout is small enough that the error bars are wide. We are advocating the policy lever, so we hold it to the same standard we held the library to: the evidence that it improves with use is real, early, and thin. It is thin.
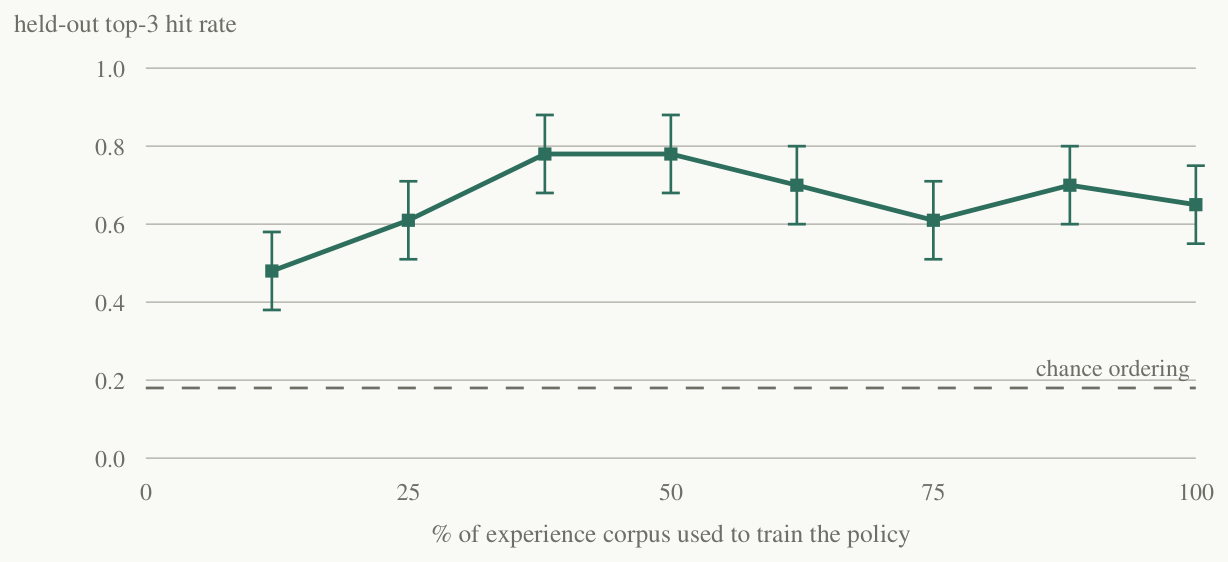
The library learned from the rare deep solve. The policy learned from every solve. That asymmetry — not library size — is where compounding lived.
Three things honest measurement revealed
First: primitive count is a mirage. For a period we grew the primitive vocabulary aggressively, and the rising count felt like progress. Then we audited it: run every primitive over a canonical probe set, group primitives whose input-to-output behaviour is identical, and subtract the ones that change nothing at all.
(F2) effective_library = |{behaviourally distinct ops}| << |{primitives}| — deduplicate by behaviour, subtract the no-ops; the honest size is what remains.
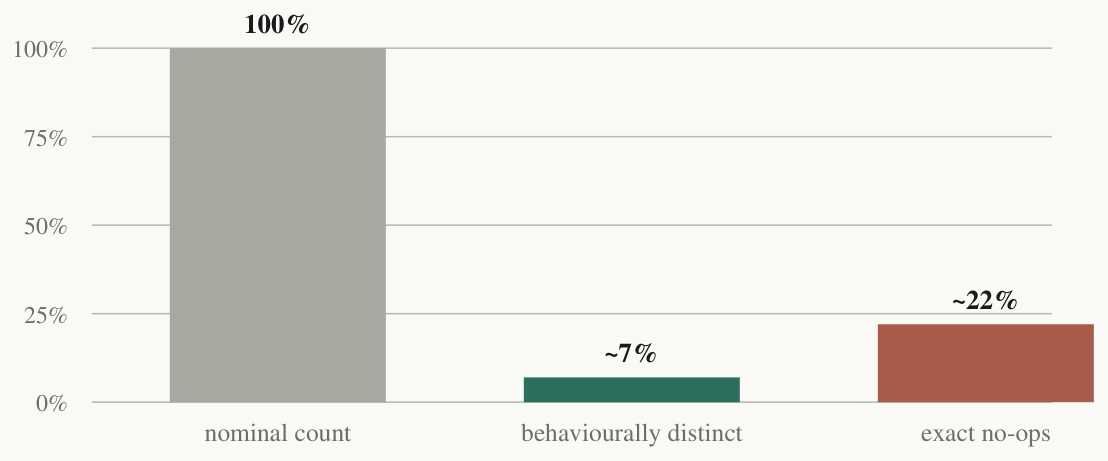
The effective library was roughly 7% of its nominal size, and more than a fifth of the entries were exact no-ops (Figure 4). Nobody padded the library on purpose; it padded itself, the way unaudited counts do. We recommend this audit unreservedly. It is a few lines of code, and it will change what your dashboard says.
Second: parametric generators beat enumeration by an order of magnitude. Library entries that generalise — schemas that take problem-derived arguments and emit a program — were roughly 15× more solve-efficient per unit added than fixed primitives. Generalisation beats enumeration inside your own library, not just inside your learner.
(F3) efficiency = problems_solved / library_units_added — parametric schemas ~ 15x enumerated primitives — a parameterised family of programs earns more per entry than a shelf of fixed cases.
Third: “never tried” is not “tried and failed,” and your logs must distinguish them. Our deep search “failed” for weeks without ever running. The two conditions produce identical aggregate metrics and opposite conclusions. Before concluding that a method does not work, verify that the search actually reached it. Of everything in this essay, this razor is the item most likely to be useful to a reader within the week.
Slope, not count
The open-endedness literature has said, with admirable frankness, that it lacks a ruler for capability that compounds, and mostly measures novelty instead (“On the Open-Endedness of Detecting Open-Endedness,” 2024). We think a serviceable ruler is available, and cheap. It needs three definitions. Experience E is the cumulative count of problems attempted, solved or not. A verified reuse event is a banked artifact contributing to the solution of a new held-out problem — one the artifact was not derived from, under a split that keeps mining and evaluation disjoint. R(E) is the cumulative count of such events after experience E. Then:
(F1) headline = dR/dE (the slope of verified reuse, held out, de-leaked, reported with uncertainty) — report how much cheaper new verified capability is getting — never how much you have stored.
Counts fail as evidence for a specific reason, not as a matter of taste: a count is monotone and unaudited. It rises under duplication, padding, and no-ops — our own library count overstated reality by roughly 14× without anyone cheating. A slope is different in kind. It only moves if new experience made future verified performance cheaper, which is the actual claim the word “compounding” makes. One caution from our own use: the slope is protocol-relative — it inherits the split, the verification gate, and the budget it was measured under, so it compares runs within a protocol, not across papers. State the protocol next to the number. And the controlled experiment in the next section supplies a second, cleaner demonstration: a condition in which the library grew while its measured gain stayed exactly zero.
A count can only go up. A slope has to be earned.
We are not alone in reaching for a rate. Enhanced POET introduced ANNECS (Wang et al., 2020), a rate-of-verified-novelty metric built for exactly this reason — raw counts mislead — though it tracks novelty rather than reuse. And a reuse-measurement line is now emerging independently: Berlot-Attwell et al. (2024) argue for evaluating reuse behaviour directly, with follow-up evaluation standards at EACL 2026 (Berlot-Attwell et al., 2026). The field is converging on reuse-based measurement from several directions; what this essay contributes to that line is the slope formulation — dR/dE, held out, de-leaked, reported with uncertainty — and the protocol-relativity caveat above.
Two clarifications, so this lands as discipline rather than slogan. Measuring the slope does not make a system smarter; it stops you believing it got smarter when it did not — those are different services, and the second is the one the field is short on. And this is not an argument against having an objective (Stanley and Lehman's warning notwithstanding): we keep an objective; we simply grade it by held-out reuse rather than by anything the system can inflate from the inside.
When would the library win? A controlled test
Our result is a counter-case, not a theorem, and its boundary is predictable. The claim we defend: library compounding tracks the depth distribution of a domain's solutions. Where solutions are deep and share structure — hierarchical construction like Minecraft's technology tree, synthesis over languages with genuinely shared subroutines like DreamCoder's domains, mathematics with its lemma reuse — banked artifacts should compound. Where solutions are shallow but conceptually varied — where the cost is discovering the one right move rather than composing many known ones — the policy is the mechanism with signal to learn from, and the library starves. There is qualitative precedent for exactly this boundary: AbstractBeam (Zenkner et al., 2024) found that library learning improved a bottom-up synthesiser only where program lengths gave abstractions something to bite on, with no significant gain on a dataset lacking shared deep structure. The controlled experiment below is the step past the qualitative form: the crossover quantified, the budget window made explicit, and the regime where the library turns harmful measured.
A prediction of this shape should be tested where the predictor can be dialled directly, so we built the smallest environment that permits it. A base language of eight operations on integer sequences; hidden transformations of controlled minimal depth (a transformation counts as depth k only if no shorter program in the base language reproduces its behaviour); deep transformations built from a shared pool of two-step motifs — deliberately the regime where libraries should win. The full loop ran at each depth setting: solve by budgeted search, verify on a held-out example, bank behaviourally-deduplicated macros incrementally, reuse them as single moves. Evaluation compares held-out solve rate with the mined library against without it, at an identical budget, across ten independent seeds.
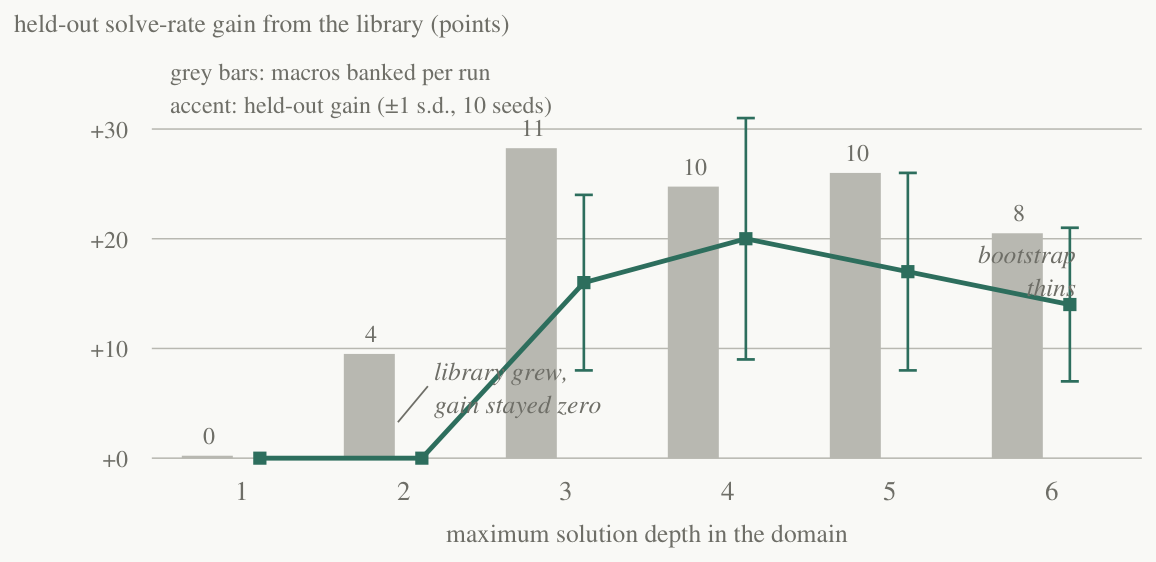
The result has the shape the hypothesis predicts, plus an honest wrinkle the hypothesis did not (Figure 5). At depth 1 the gain is exactly zero, for the analytic reason: there is nothing multi-step to bank. At depth 2 the library grew — about four macros per run — while the gain stayed exactly zero, because blind search already covered depth two within budget: a growing library with nothing to add, the count-versus-slope distinction reproduced in miniature by a system with forty lines of logic. At depths 3 and 4 the library lifts held-out solve rate by 16–20 points — banked macros collapse deep solutions into short ones, putting them back inside the budget. And at depths 5 and 6 the gain persists but tapers (+17, +14): the miner solves fewer problems at all, so it banks thinner coverage of an exponentially larger space. Compounding is real where depth exists; it is not unbounded.
Varying the search budget instead of the depth completes the picture, and answers the natural objection that “depth” is doing unexamined work. At a lavish budget — blind search covers depth three exhaustively — the depth-3 gain vanishes: the library is redundant. At a starved budget, the depth-2 gain turns negative (−8 points ±8): every banked macro widens the branching factor, and under a tight budget that dilution costs more than the macros return. A library entry is never free — the mirage of Figure 4 is not merely cosmetic. Putting the two sweeps together:
(P2) library_gain > 0 only when D_blind(budget) < solution_depth <= D_macro(budget) — the library pays off exactly in the window between what blind search already reaches and what macro-extended search can reach; below the window it is redundant, beyond it unreachable — and everywhere, each entry costs branching.
So the honest form of the hypothesis is relational: what predicts compounding is the depth distribution of a domain's solutions relative to the searcher's blind reach. Stated that way, it makes predictions we have not tested — and we would rather state them and be wrong than imply them and be safe:
| Domain family | Expected depth mass | Predicted lever |
|---|---|---|
| Hierarchical construction (crafting, assembly, task stacks) | deep, heavily shared | library |
| Program synthesis over rich shared-subroutine languages | deep, shared | library, policy-guided |
| Symbolic mathematics (lemma reuse) | deep, shared | library + retrieval policy |
| Web and UI agents | shallow, site-specific variation | policy |
| One-shot concept induction (this essay) | shallow (88% depth one) | policy |
This yields a procedure rather than a position. Before building the library, measure the depth histogram of your own solved problems (Figure 1 took an afternoon). If the mass sits at depth one, build the ranker first; the shelf can wait. If the mass sits deep, the shelf is the lever and the canonical architecture is right. Both mechanisms are non-parametric — no gradient steps, no retraining — so this is not a gradient-versus-memory argument. It is an argument about where, in a given domain, the compounding actually lives, and a claim that one cheap measurement predicts it. We have now tested that claim observationally in one natural domain and causally in one controlled family. It is stated here so it can be falsified in yours.
What this is / what this isn't
This is a measured counter-case to the library-compounding assumption in one adversarial domain, a controlled synthetic demonstration of the depth mechanism behind it, and a reporting discipline — the slope of verified reuse — aimed at a gap the open-endedness field has itself named.
This isn't a refutation of library learning (the boundary is stated above, and the controlled experiment shows the library winning inside a predictable, budget-relative window); a benchmark result or leaderboard claim (no scores appear here, by design); or a claim about LLM agents (the system is a symbolic searcher with a small learned ranker — no large model reasons anywhere in the loop).
Run this on your own system
- Depth histogram. Take every solved problem; record the step-count of its solution. If the mass sits at depth one, expect policy compounding, not library compounding, to be your lever.
- Behaviour audit. Run every library entry on a canonical probe set; group identical input→output maps; subtract no-ops. Report the effective size next to the nominal one.
- Never-tried check. For any method judged to have failed, verify from logs that the search actually reached it. “Skipped” and “failed” produce identical aggregates and opposite conclusions.
- Slope, not count. Report dR/dE — verified reuse events per unit of experience, held out and de-leaked — with uncertainty. Retire the stored-skill count to a diagnostics page. A worked reference implementation of the controlled counterpart to step 4 is linked in the reproduction note below.
Reproducing the controlled experiment (Figure 5)
Base language: eight operations on integer sequences of length 8, values mod 10 — reverse, negate, successor, double, rotate-right, swap-halves, adjacent-pair swap, cumulative sum. Motifs: four two-step compositions per seed, each verified to equal no shorter program. Tasks: a hidden transformation of verified minimal depth k, drawn uniformly from {1..d}; three training pairs and one held-out pair; exact match only.
Loop: 40 mining tasks with incremental banking (a solved multi-step program becomes a macro if its behaviour on 20 probe sequences duplicates no existing operation), then 30 evaluation tasks scored with and without the mined library at an identical budget of 150 candidate-program evaluations, maximum program length 4. Ten seeds per condition; Figure 5 reports mean ±1 s.d. The budget sweep reruns depths 2–3 at 40 and 600 evaluations. Total runtime: minutes on one CPU core.
The natural-domain system is deliberately described only by ratios (Section 2); the controlled experiment is specified in full so that the mechanism, at least, is reproducible end to end.
The full experiment — script, fixed seeds, and the reference results it must reproduce — is public at github.com/MC-MatthewChilds/honest-measurement (article3-depth-dial/); it is standard-library Python and runs in minutes on one CPU core.
Limitations
One natural domain, chosen adversarially. Our benchmark is designed to resist memorisation, which is close to a worst case for libraries. The ~19× signal-capture asymmetry is a property of this domain's depth distribution, not a universal constant.
The controlled experiment is a toy, and its substructure is given by construction. It demonstrates the depth mechanism cleanly — including the analytic zero at depth one — but it cannot say how often natural domains supply the shared substructure that made the library win at depths three and four. That is exactly the question the depth histogram answers per-domain. The taper at depths five and six is a further reminder: even where the library wins, its gain is bounded by the miner's own reach.
The policy's learning curve is early evidence. A corpus of roughly a hundred examples, a small holdout, wide error bars, and a plateau at current scale (Figure 3). Policy compounding is the better-supported mechanism here — not a proven law.
The full scaling ablation in the natural domain is pending. We have not yet isolated the policy's compounding gain from concurrent capability additions across an entire growth curve there; the controlled family isolates the library's contribution, not the policy's. We will report it either way.
All natural-domain ratios come from one system and one program language. The depth-histogram prediction is now supported observationally and in a controlled toy; it remains untested in other natural domains, and the table of cross-domain predictions is exactly that — predictions. We consider them the most falsifiable claims in this essay, which is why they are here.
Independent support now exists in a third domain family: the theorem-proving counter-cases of Berlot-Attwell et al. (2024; 2025) found the same starved-library phenomenon in LLM-based learners.
Why it matters
The agents field is investing heavily in memory — skill libraries, solution archives, retrieval stores — and most public evidence for that investment is a count. Counts are exactly the quantity this essay found inflated by ~14× in its own system, with nobody cheating; and in the controlled family, a growing count coexisted with a measured gain of zero. The disciplines offered here — the depth histogram, the behaviour audit, the never-tried check, the slope of verified reuse — cost a few lines of code and one dashboard change, and together they predict where compounding will live before the investment is made. The honest object is a slope you own and reality grades — not a threshold someone else scores. And that is the connection to generality this series has been circling: a general system is not the one that has stored the most; it is the one whose next unknown keeps getting cheaper because of what it verified before. The slope of verified reuse is that quantity, measured. Everything else is inventory.