Epistemic status: a discipline I actually run, learned from two failures inside my own research system, one of which nearly redirected months of work. I hold the central asymmetry claim at roughly 90%, and “the full protocol is worth its cost for most serious eval teams” at more like 65%. Most of the evidence comes from one research program plus one at-scale natural experiment from the field, and section 12 says where I would update.
1 · The loud error and the silent one
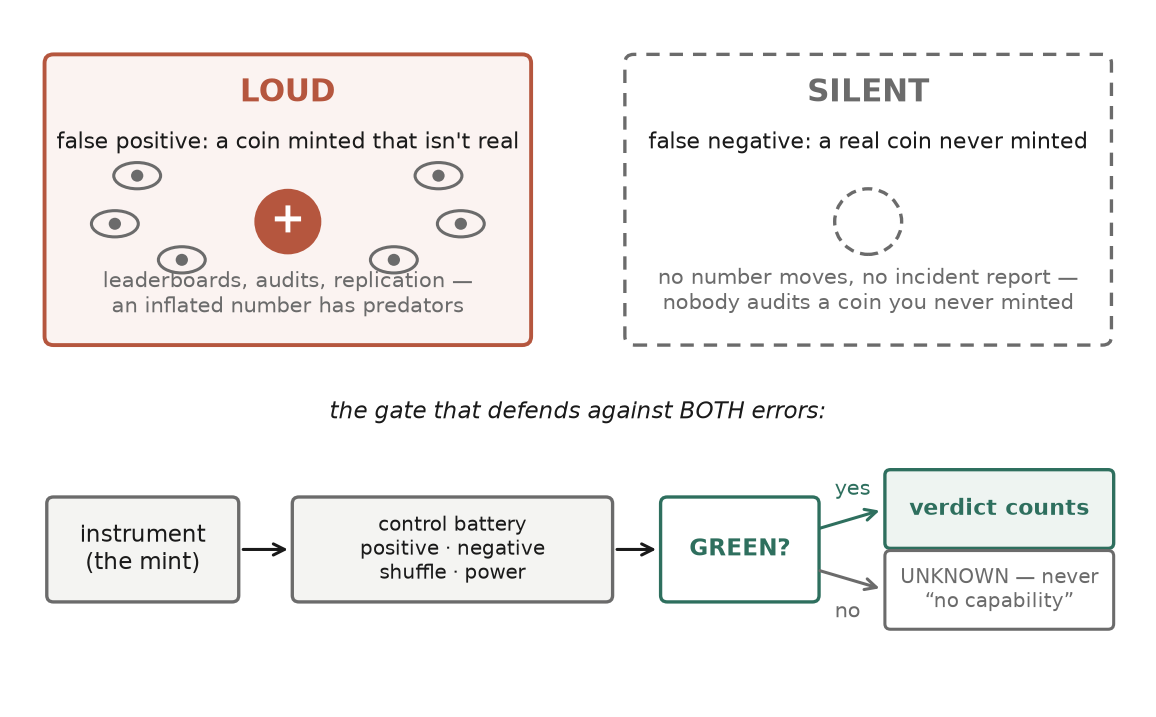
Two errors can corrupt a reward system. The first: the system claims a capability it does not have. A number on a dashboard is too high. This error is loud. Nearly every honesty mechanism the field has built points at it — leaderboards get audited, contamination gets hunted, reviewers demand baselines and error bars, and someone, eventually, reruns the eval. When it happened inside my own system — an audit found the ledger’s recorded difficulty inflated roughly nineteen-fold over the true complexity of the methods used — the discovery felt almost routine. Inflation is the failure everyone is watching for. It has predators.
The second error: the system quietly develops a real capability, and the instrument that grades it scores the gain as zero. Nothing on any dashboard moves. There is no wrong number to audit, because there is no number. The verdict gets filed as settled knowledge — we tested that; there’s nothing there — and research steers away from a live direction. When this happened to me, a grader reported “no transfer” across an entire family of tasks where transfer was, it turned out, close to the achievable ceiling. Nothing caught it for weeks, because nothing was looking. A false positive is a loud lie. A false negative is a silent one.
Nobody audits the coins you never minted.
This asymmetry has neighbours in the literature, and by now the phenomenon itself is well documented. Capability-elicitation and sandbagging work (van der Weij et al. 2024; METR’s elicitation-gap studies) worries that a model underperforms, so you underestimate what it can do; this essay worries that your grader silently discards a real gain. And the incident reports on the grader side have started arriving: a strict parser that reported zero accuracy where a corrected parser recovered three-quarters, on identical outputs (Garware & Zisad 2026); verifier false-negative rates of ten to sixteen percent measured inside RL reward loops (Xu et al. 2025); label errors whose correction flipped leaderboard rankings (Vendrow et al. 2025); benchmark bugs whose repair revealed agents substantially stronger than reported (Zanoli et al. 2026); and — the field’s own smoking gun — an error-corrected re-release of a frontier mathematics benchmark on which a frontier model’s score roughly doubled, from about a third to about three-quarters, with zero change in the model (Epoch AI 2026). The agent-evaluation literature now says the quiet part plainly: outcome metrics can inflate or deflate capability (Kirgis et al. 2026).
So the phenomenon is documented. What the incident reports do not supply — each one a discovery made once, by hand, after the fact — is the standing discipline that would make catching these errors routine: the named incident class, the admissibility gate, the rule for what a null is allowed to mean. That is this essay’s job. To be plain about the hierarchy: the doctrine — treat every capability grader as an instrument requiring two-sided validation — is the contribution; the reward economy is the implementation I learned it inside, and section 10 applies the doctrine where most readers live, language-model evaluation. What follows: the economy’s design, two failures I caught in my own system — one loud, one silent — and the discipline they forced.
2 · What a coin is
A coin is one verified, non-trivial unit of capability gain. It is created only when an external verifier — a proof kernel, a hard test suite, a real-world outcome that resolved after the prediction was frozen — confirms a result the system did not already have. Four gates must hold simultaneously, and the conjunction is the whole design:
(F2) mint ⇔ verified_external ∧ out_of_sample ∧ (lift > 0 vs frozen baseline) ∧ leakage_clean — reads as: a coin exists only if all four gates hold — reality mints; the system never prints.
“Reality mints” is a slogan until it is a chain, so here is the chain, each link with a checkable property. An external outcome: the event being predicted resolves after the prediction is frozen, by a process causally independent of the system being graded — that independence is what the word “reality” means here. A frozen protocol: the baseline, the grading rule, and the admission window are pre-registered; no post-hoc selection of which predictions enter the pool. An independent verifier: the agent that mines a coin may never stamp it. Only then, the mint. Break any link and the currency is being printed, not minted.
(F1) coin_value = difficulty × value × confidence, confidence ∈ [0, 1] — reads as: a coin is worth what it cost to earn, times what it changed downstream, discounted by evidence strength — and no multiplier can ever inflate a coin above its evidence.
Difficulty is anchored to externally observable quantities only — proof length, search depth, margin over the frozen baseline — never to a scalar the system assigns itself, because the weakest joint in any reward ledger is a self-assigned number. Value is harvested, never claimed: it mints only when a result later proves load-bearing. Hard and valuable together is the jackpot; neither pays approximately nothing; no single axis can pay a jackpot. Two more properties matter. The ledger is append-only, but a coin can be reversed — de-coined by an independent assayer when its verifier turns out weak, its baseline stale, or leakage is found; the total nets down. And every candidate that fails a gate is logged, with the version of the instrument that rejected it — a detail that will carry most of this essay’s weight in section 9.
The idea has a neighbourhood, and it is worth naming early. Internal economies of agents go back at least to Baum’s Hayek machine (1999) and Holland’s classifier systems, whose bucket-brigade credit assignment famously bred parasites — agents that got rich by positioning themselves near reward rather than doing work; that parasite is the villain this design tries to breed out. The nearest contemporary neighbour in spirit is the “Economy of Minds” line (Qi et al. 2026). The minting standard — only externally checkable wins count — is the same instinct as reinforcement learning from verifiable rewards (Lambert et al. 2024), applied not to a gradient step but to library membership: what the system is allowed to remember as knowledge. And the failure the gates defend against is the Goodhart canon (Manheim & Garrabrant 2018; Gao et al. 2022), cited here once and not re-explained.
3 · Why pay in generality, not task reward
If the currency is task reward, the parasite strategy is obvious: get rich by overfitting the current game. Every Goodhart variant is some version of this. The defense is to change the denomination: the highest-paying coins are transfer coins, minted only when a mechanism learned in one process demonstrably predicts a different process, out-of-sample, better than that process’s own frozen baseline. You cannot get rich by winning the current game; you get rich by becoming more general. Here is the definition this essay operates with:
(F3) generality G = #{ distinct processes connected by genuine transfer edges } edge A→B genuine ⇔ GREEN instrument scores zero-shot skill(A→B) ≥ θ · ceiling(B), out-of-sample, above the power floor distinct ⇔ different governing law (driver set + response form) — never geography or topic headline: XQ_web = 100 · min(1, G / 30) — reads as: generality is the size of the web of law-distinct processes your learned mechanisms genuinely predict — a dense web of many small transfers, not a few large ones.
The load-bearing word is distinct. Transfers are counted by mechanism, never by geography or topic: a model that predicts the same phenomenon in a second city has demonstrated robustness, which is good, but it has not demonstrated a new process, so it earns nothing new. This single rule removes the cheapest inflation channel I know of — replicating one success across near-identical instances and calling each one progress. What makes the denomination Goodhart-resistant is that the coin is expensive to fake: to counterfeit a transfer coin you would have to genuinely predict a held-out process against its own best baseline, and at that point the counterfeit is the capability. The baseline, throughout, is the ruler and never the goal. Where this sits relative to the standard reward schemes:
| scheme | reward denominated in | verified by | canonical failure | false negatives… |
|---|---|---|---|---|
| task-reward RL | environment return | the reward function itself | reward hacking / wireheading | invisible — nothing looks for them |
| RLHF | human preference | a learned reward model | reward-model over-optimization (Gao et al. 2022) | unexamined |
| RLVR | verifiable task outcomes | external checker, per task | verifiable ≠ general; narrow coverage | not addressed |
| static benchmarks | score over a fixed set | the test set | contamination, saturation, teaching to the test | a low score is read as “can’t” — rarely re-asked |
| coin economy (this essay) | verified generality (transfer) | independent verifier + frozen baseline + battery-GREEN instrument | slow; mints few coins by design | explicitly policed: control battery + re-gradeable graveyard |
WHAT THIS IS / WHAT THIS ISN’T
What this is: an eval doctrine plus a working internal economy, illustrated with measurements on public physical time-series data across three domain families. Every number in this essay is out-of-sample for the thing being claimed, scored against a stated frozen baseline, and the instrument that produced it passed a control battery first.
What this isn’t: a claim about general intelligence; a benchmark result; or evidence of transfer between different physical laws — the same-law results below are exactly what they say and no more, and cross-law transfer remains an open frontier, not a settled yes or no.
4 · War story I: the audit that cut the ledger (the loud error)
The economy’s first serious failure was the classic one. The mining fleet was productive, the ledger grew, and the cumulative recorded difficulty grew with it. Then an audit re-priced every coin by the true complexity of the method it used — rather than the size of the instance it was used on — and found the recorded total inflated roughly 19×. In the worst vein the gap was over a hundred-fold. The pattern underneath was humbling in its banality: the thousandth application of the same method to a bigger instance had been priced like the first. The coin count was real; the capability it implied was mostly padding. In psychometric terms this was a construct-validity failure (Cronbach & Meehl 1955): the count had stopped measuring the construct — capability — it was built to track.
The response was mechanical, because the charter had been written for this: the ledger is allowed to fall. Difficulty was re-anchored to method rungs, and a separate honesty pass over the headline score — de-duplicating breadth, expelling internal-action metrics from an external ruler, enforcing per-row statistical significance — cut it by roughly two-thirds. On another occasion the score went down when a real-but-weak capability was counted for the first time, and that is the intended behaviour: the score tracks reality, not the desire for a bigger number.
The ledger is allowed to fall; that is what makes its rises mean something.
Here is the point of telling this story first: it was caught by ordinary diligence. Inflation is loud. An audit had a number to pull on, the number was wrong, and the correction followed. Every part of that sentence fails for the second story.
5 · The mint is an instrument, and instruments lie
Denominating reward in generality has a cost: someone has to measure transfer, and that measurement is an instrument in exactly the laboratory sense — a constructed procedure that turns the world into a number. Instruments drift, break, and lie, and the two directions of lying are not symmetric. An instrument that over-mints produces a rising number that people will eventually interrogate. An instrument that under-mints produces… nothing. A rejection. A null. The most dangerous property of a broken grader is that its output is indistinguishable from the true absence of capability.
None of this is new — it is just new to us. Clinical laboratories have run the full discipline at civilization scale for four decades: known control materials are assayed alongside every batch, and when the controls fail a Westgard rule, every patient result from that run is quarantined until the instrument is requalified (Westgard et al. 1981) — guilty until GREEN, enforced daily in tens of thousands of labs. Assay validation requires a stated limit of detection before a negative result may be reported as negative — that is this essay’s power floor. Metrology ties every instrument to reference standards through an unbroken calibration chain (BIPM VIM 2012) — that is the positive-control battery. Psychometrics has interrogated whether a score measures its construct since Cronbach & Meehl (1955) — that is the clawback. And the false-positive/false-negative trade has had a formal calculus since signal detection theory (Green & Swets 1966), with its statistical-power discipline (Cohen 1988) only now arriving in AI evaluation (Miller 2024). The contribution of this essay is not any one of these ideas; it is the transplant — treating the graders of AI capability with the same suspicion every mature measurement science already applies to its instruments. The next section is the war story that forced the transplant on me.
6 · War story II: the ruler that agreed with everyone (the silent error)
In late June 2026 I built a grader to answer the question the whole economy hangs on: when my system learns a mechanism in one domain, does anything genuinely transfer to another? The grader’s design looked reasonable: reduce each domain to a signal index, fit the relationship on source domains, evaluate on a held-out target. Its verdict was damning — essentially no cross-mechanism transfer anywhere. Diversity of mechanisms didn’t help. The system, it said, was an encyclopedia, not a generalizer. I believed this for about two weeks, and had started re-planning the research program around it.
The diagnostic that saved it was embarrassingly simple. For any fixed target, the grader’s “transfer” score was numerically identical regardless of which source it transferred from — a physically related source, an unrelated one, and a shuffled one all scored exactly 1.64. A score that does not respond to the source is not measuring transfer; it is measuring a property of the target alone. Two design sins had compounded: collapsing each domain to a single scalar washed out the source’s identity, and re-fitting a coefficient on the held-out target let the target’s own structure masquerade as transferred knowledge. The grader was answering “is this target weakly self-predictable?” — and calling the answer “no transfer.”
Swap the source. If the score doesn’t move, you’re measuring the target, not the transfer.
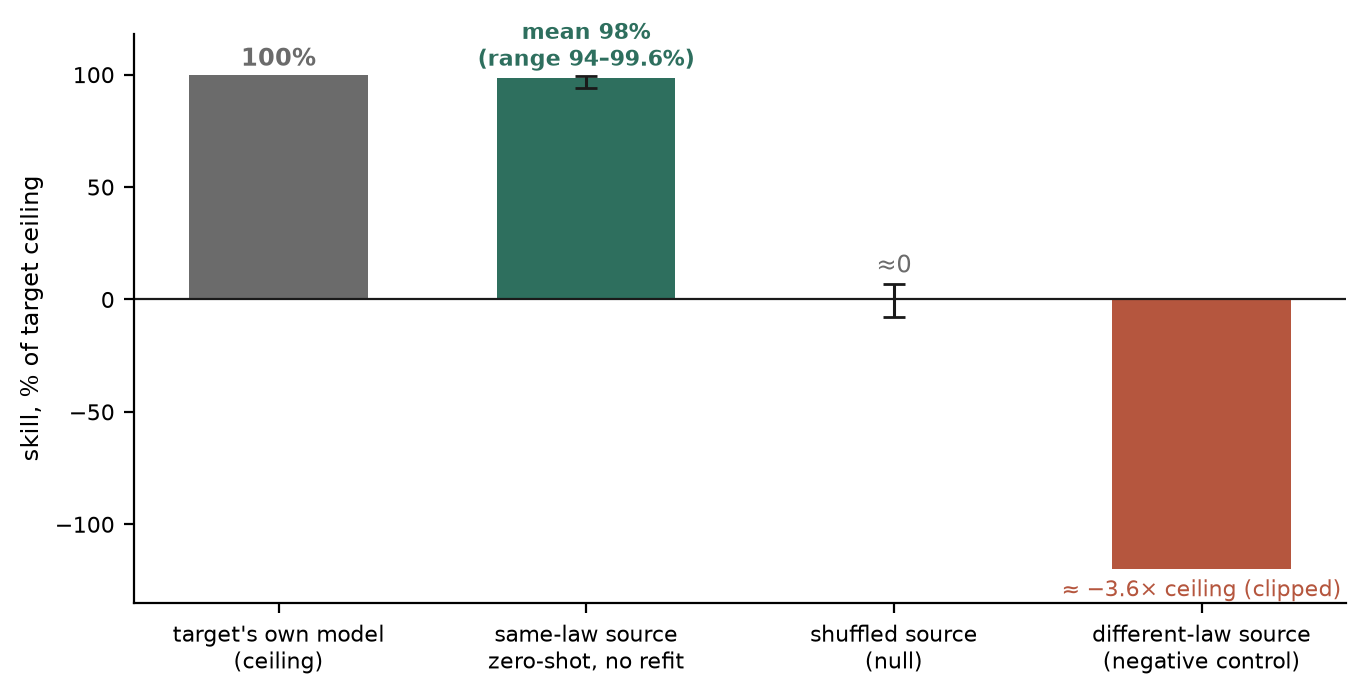
The fix inverted both sins: fit the source mechanism’s full model on the source only, apply its coefficients to the target’s features with zero refit, and score against the target’s residual-mean baseline, comparing to the ceiling set by the target’s own model. Then — the doctrine’s seed — validate the fixed instrument on a pair chosen a priori such that transfer must exist if the instrument works: two primary pollutants at the same site (NO2 and CO), both governed by the same dilution law under the same drivers (boundary-layer height and wind). Different pollutants, one physics.
The corrected instrument recovered that pair at ~98% of the achievable ceiling, in both directions, with zero data from the target. To make sure that wasn’t a lucky pair, I extended the test to a grid: three law-sharing pollutant species across three inversion-prone cities, six months of hourly data (~4,400 observations per series). Every ordered same-law pair transferred at 94–99.6% of its target’s ceiling (mean ≈98%). The learned coefficients of law-sharing models agreed to within a few percent — they had converged on the same physics. And the negative control behaved exactly as a negative control should: a different-law source (photochemical ozone) was not merely unhelpful but actively destructive, scoring several times the ceiling below zero, while shuffled sources scored approximately nothing. The source now matters enormously — which is precisely what “measuring transfer” means.
Honest scope, before it sounds too good: these series are hourly reanalysis products, so the same modeled meteorology drives all species at a site — near-ceiling transfer is partly a property of the data’s cleanliness, and the claim is not new atmospheric physics. The claim is about the instrument: on identical data it now cleanly separates law-sharing pairs from non-law-sharing pairs, where its predecessor had declared them all equally dead. The broken grader’s verdict — flat slope, encyclopedia, no transfer — was an artifact of the ruler, not a fact about the world. That is what a silent false negative looks like from the inside: a plausible, precise, wrong “no,” aimed at exactly the capability the whole economy was built to grow.
7 · The third domain: an instrument that can say no
A doctrine validated only where it succeeds is advertising, so the third replication was chosen to be harder. The domain family is the land water balance — shallow soil moisture, deep soil moisture, and river discharge, on daily data over two years at three catchments — mechanisms that share a driver (precipitation forcing and evapotranspiration demand) but not, it turns out, a response form: the shallow store responds in days, the deep store integrates over weeks, and discharge is routed through a whole catchment. My a-priori hypothesis was that all three would cluster as one law. The instrument said otherwise, and the battery gives me reason to believe it.
The controls behaved exactly as in the first two domains: every different-law negative control (a thermal mechanism fit on the same features) was catastrophic — several times the ceiling below zero — and every shuffled source scored negative. But the same-driver verdicts were now heterogeneous, and correctly so. In the direction the physics permits — from the slowly-integrating store toward the fast one — transfer ranged from marginal to four-fifths of ceiling depending on site. In the reverse direction it was consistently absent or destructive. And where a target had no measurable ceiling at all under the shared features (a third of the candidate targets), the power floor returned UNKNOWN rather than “no transfer.” The a-priori law-cluster hypothesis was simply wrong at the feature level, and the doctrine’s own rule — cluster by shared law, same driver and same form, never by topic — was the correction.
The heterogeneity is the point. Across three domain families the same instrument now produces three distinct readings: near-ceiling transfer where mechanisms share driver and form (the pollutant grid), partial and directional transfer where they share a driver but not a form (hydrology), and catastrophic failure where they share neither (every negative control, everywhere). A ruler that read near-ceiling everywhere would be suspicious — it would suggest the data, not the instrument, was doing the work. A ruler that can produce all three readings, and returns UNKNOWN when underpowered, is measuring something.
8 · Guilty until GREEN: the control battery
The generalized lesson is a rule about admissibility, not about any one bug. An instrument’s verdicts — including its rejections — are inadmissible until the instrument passes a fixed battery of controls, re-run every time the instrument changes:
- Positive controls. Pairs where the capability is known to exist — chosen a priori, hidden from the instrument’s development — that it must recover at a substantial fraction of ceiling and several times the minimum detectable effect. An instrument that misses a known-genuine coin under-counts silently; this is the check with no natural constituency, and the most important one on the list.
- Negative controls. Pairs where the capability is known absent, bounding the false-positive rate.
- Shuffle-null. Break the source’s internal pairing and re-run: if a shuffled source still scores, the instrument leaks.
- Source-dependence. The war-story tell, promoted to a standing invariant: across unrelated sources into one target, the score’s spread must be large; a source-invariant score measures the target.
- No-refit. Nothing is ever fit on the held-out target.
- Power floor. The instrument’s minimum detectable effect must be smaller than the smallest coin worth minting; otherwise its nulls are vacuous.
(F5) verdict is VALID ⇔ instrument is GREEN GREEN ⇔ positive controls ∧ negative controls ∧ shuffle-null ∧ source-dependence ∧ power ≥ floor null verdict from a non-GREEN or underpowered instrument = UNKNOWN, never NO-TRANSFER — reads as: an instrument is guilty until proven GREEN, and an inadmissible “no” is an unknown, not a negative.
In diagnostic-testing terms, the battery is nothing more exotic than a measured error profile: the positive controls estimate the instrument’s sensitivity at the effect size of a known-genuine coin — an upper bound on its silent miss rate; the negative controls and shuffle-null estimate its specificity — a bound on its false-positive rate; and the power floor states the smallest effect for which either bound means anything at all. The battery’s design principle is symmetry: for every anti-inflation gate, a paired anti-miss sensitivity check. The field builds the first kind reflexively — contamination scans, held-out sets, frozen baselines — because false positives are policed. Nobody demands the second kind, because a missed capability files no complaint. You have to install its advocate deliberately.
A sharp reader will notice the battery is assembled, not invented — and that is correct. A solvability check that runs the known solution through the harness ships today in the UK AI Security Institute’s cyber-evaluation framework, explicitly to prevent false negatives (UK AISI 2026); null-agent audits prescribing negative controls are on the record (Berkeley RDI 2025); the power discipline is Miller’s (2024). What exists nowhere, to my knowledge, is the conjunction: the checks fused into a single GREEN/not-GREEN admissibility gate; the source-swap promoted to a named standing invariant; the epistemic rule that a null from a non-GREEN instrument is UNKNOWN rather than a negative; and the explicit transplant of clinical QC’s quarantine discipline (Westgard et al. 1981). The claim is unification, not invention — which is also how clinical QC itself came to exist.
9 · The re-gradeable graveyard — and a re-grade that minted nothing
One consequence of instrument fallibility is that a rejection is a statement about the instrument as much as about the candidate. So rejections are never discarded: every failed candidate is logged append-only with the full measurement, the reason it failed, and — crucially — the version of the instrument that failed it, flagged re-gradeable. When the instrument improves, the graveyard is re-mined. A rejection means “failed instrument vN,” never “not a coin.” Every “no” carries an expiry condition.
I ran the first full re-grade while preparing this essay, and it is worth reporting precisely because of how it came out. The candidates were cross-mechanism transfers in a fourth family — wind-forced coastal processes: storm surge, wave height, currents, lake seiche — all rejected months earlier by an instrument using instantaneous wind and pressure features. The upgrade was physically motivated and chosen before seeing any outcome: water responds to integrated forcing, so the new representation adds exponential memories of wind stress at several timescales. Doctrine first: the upgraded instrument had to earn GREEN, and did — it recovered all of its known-genuine positive controls (same mechanism across different stations) at 76–100% of ceiling, and every shuffle-null died.
Then it re-tested the entire graveyard. Result: zero recoveries. About a quarter of the rejections were reclassified UNKNOWN rather than “no” — their targets showed no measurable ceiling at all under the instrument’s features, and an underpowered null is not a negative. One candidate turned out statistically real but tiny — confidently above zero and still only ~4% of its target’s ceiling — and the gate correctly refused it: significant is not the same as load-bearing. The detail I find most persuasive: the upgraded representation raised some targets’ ceilings roughly tenfold — a far better instrument — and the gates still refused to mint. The re-grade machinery demonstrably does not manufacture recoveries to justify its own existence.
That claim now has a stake attached. Pre-registered prediction: as instruments upgrade across these domain families, graveyard re-grades will recover genuine coins at a nonzero rate. If, after several more upgrade cycles, the recovery rate is still zero, then either my instruments improve too slowly to matter or the graveyard is theater — and this series will report that outcome either way.
10 · The doctrine where you live: language-model evals
Nothing above requires an internal economy, physical time series, or my lab. The reader most likely to need this doctrine runs language-model evaluations, where grader-side false negatives are endemic and mostly unexamined: a strict answer parser scores a correct-but-differently-formatted answer as wrong; a broken tool endpoint in an agent harness silently reads as “the model can’t use tools”; a truncated context or a capability-suppressing system prompt turns a real skill into a zero. The elicitation-gap literature measures exactly this distance — between what a model can do and what your harness got it to do — and every point of that gap is a coin someone’s grader refused to mint.
Each element of the battery transplants directly. Positive controls: seed every eval run with canary cases the model under test (or a reference model of known ability) is known to solve; if the harness misses them, quarantine every verdict from that run — the failure is in the pipeline, not the model. Source-dependence: swap the model. If scores barely move across models known to differ, the eval is measuring the harness, not the model — the same tell that caught my broken grader. Power floor: an eval too small to detect the smallest effect you would act on cannot return “no capability” (Miller 2024); it can only return UNKNOWN. The re-gradeable graveyard: log every “model can’t do X” verdict with the harness version that produced it, and re-run the can’ts when the scaffold improves — most labs improve their scaffolds constantly and re-grade nothing, which means their capability maps silently rot in one direction.
None of this needs new machinery; it needs a few known cases, a log file with a version stamp, and the habit of treating a null as a claim about the instrument until proven otherwise. Everything in this essay runs on public data, and the battery is a protocol, not a codebase — any group can run it against its own graders tomorrow. The field has, in fact, already performed one graveyard re-grade at scale: the error-corrected re-release of a frontier mathematics benchmark, on which scores roughly doubled with zero change in the models (Epoch AI 2026), is exactly a re-grade of rejected verdicts — performed manually, once, heroically, without the versioned machinery that would make it routine. The doctrine’s proposal is that this should not require heroism.
11 · The asymmetry, restated
Consider where the field’s honesty budget goes. Almost all of it — correctly, and well — is aimed at false positives. The closest thing to an anti-false-negative literature is capability elicitation and sandbagging, and it is aimed at models, not at the instruments that grade them. Yet every failure mode in that literature has a grader-side twin, and the grader-side twin is worse, because a sandbagging model is at least suspected by construction, while a broken grader’s null arrives wearing the authority of a measurement. The economics of the gap fit in three lines:
(F6) attention_i ∝ rate_i · detectability_i (errors you SEE become incidents) harm_i ∝ rate_i · (1 − detectability_i) · cost_i (errors you KEEP compound quietly) detectability_FP >> detectability_FN ⇒ attention concentrates exactly where the harm is not — reads as: a field that allocates scrutiny by incidents will, under asymmetric detection, systematically under-police its most expensive error class.
A fair question from reviewers of an earlier draft: is the coin economy required, or does the evaluation doctrine stand on its own? The doctrine stands alone — any lab that grades capabilities needs control batteries, power floors, and re-gradeable rejections, whether or not it runs an internal currency. But the two are complementary in a specific way: an economy without the instrument discipline simply Goodharts itself more elaborately, and a doctrine without an economy protects nothing anyone is forced to care about. The economy is what turns a missed capability from an abstract error into a mispriced asset — it gives the silent failure a victim with a balance sheet. The fix for the asymmetry is not vigilance, which attaches to events; it is structure: denominate reward in something reality must co-sign (the coin), treat every verdict-producing instrument as guilty until GREEN (the battery), and give every rejection an expiry condition (the graveyard). The honest object underneath all three is the same: a slope you own and reality grades — not a threshold someone else scores.
12 · Objections, and where I might be wrong
The strongest objection I know to this doctrine is that the UNKNOWN rule looks like a get-out-of-jail-free card: if any null can be attributed to a non-GREEN instrument, can’t I dismiss every unwelcome negative forever, on the theory that the instrument just isn’t good enough yet? I take this seriously because it describes a real failure mode of mine in waiting. The answer is that the doctrine cuts both ways. A null from a GREEN, adequately powered instrument is not merely admissible — it is stronger evidence of absence than an ordinary null, because sensitivity was demonstrated on the same apparatus that produced it. The battery is what makes “no” meaningful, not what makes it impossible. And the discipline is versioned and logged precisely so that motivated non-GREENness is visible: an instrument kept perpetually unvalidated around one unwelcome conclusion would show up in the record as exactly that. The zero-recovery re-grade in section 9 is this pattern working as intended — the machinery visibly refuses to bend toward the answer that would flatter it.
The second objection is cost, and it is partly right: two-sided validation is overhead, and the trade will not favor the full battery everywhere. My honest split. Positive controls plus the source-swap cost a few percent of an eval budget and catch the two failure modes with the worst silent-cost profile; I hold “most serious eval teams should adopt at least that minimal pair” at roughly 85%. The full six-check battery with a versioned graveyard earns its keep when verdicts feed decisions that are expensive to reverse — training bets, safety cases, deployment gates — and is probably overkill for quick informal comparisons; I hold “the full protocol pays for itself broadly” at more like 65%, and I would rather see the minimal version adopted widely than the full version admired and skipped.
Third: isn’t this just Goodhart’s law again? Adjacent, not identical. Goodhart failures come from optimization pressure against a proxy; a false negative attracts no optimization pressure at all — nobody Goodharts toward a lower score — which is exactly why the standard anti-Goodhart toolkit (frozen baselines, held-out sets, contamination checks) never catches one. The two failure classes need different immune systems, and the field has so far built only one of them.
Where I might be most wrong, with the updates that would move me. The asymmetry could be smaller than I think in mature benchmark ecosystems — label-error audits and harness validation may be becoming routine faster than an outsider can see, and a survey showing eval teams already re-grade their nulls after scaffold changes at any meaningful rate would substantially deflate this essay’s thesis; I would report that. The vividness of the error-corrected mathematics benchmark may be doing more work in my head than one datapoint deserves. And the physical-data validations establish the instrument’s discrimination on one region and season of clean data, as the Limitations say — a failed replication of the same-law grid elsewhere would force a rewrite of section 6. If you run the battery on your own graders and find nothing, that is genuine evidence against the size of the problem, and the contact line at the end of this essay is there for exactly that message.
Limitations
Denominating reward in verified generality is slow and expensive; the economy mints far fewer coins than a task-reward economy would, by design, and that trade will not suit every system. The atmospheric grid, while consistent across every pair tested, comes from reanalysis data in one region and season, and it validates the instrument’s discrimination, not new physics; the hydrology replication shows the instrument can refuse and return UNKNOWN, but it also shows my own a-priori law-clustering was wrong once already, and it will be wrong again. Transfer between different physical laws — the scientifically interesting case — remains open. The control battery is itself an instrument and can itself be underpowered; the power floor and the re-gradeable graveyard are the hedge, so that today’s “no” can become tomorrow’s “yes” without anyone having to remember to ask. The graveyard is young — one instrument family and a single upgrade cycle so far — and its zero-recovery result, while evidence the machinery doesn’t invent coins, is not yet evidence it finds the ones that exist; the pre-registered prediction in section 9 is the test. A theory reader will notice the equations here define commitments rather than derive guarantees; incentive-compatibility and formal bounds on false-negative rates are the natural next paper, not this essay. And one reflexive point should be said aloud: the strongest criticism of this essay — that its evidence comes mostly from one research program — is this essay’s own thesis applied to itself. The doctrine predicts that its external validation will arrive slowly and silently or not at all, unless others run the battery on their own graders — section 10 is written to make that as easy as possible. The 2025–26 incident literature cited in section 1 is encouraging on exactly this point: the field has begun documenting the failure class this essay names.
Why it matters
Measurement infrastructure quietly determines what a field believes is possible, and therefore what it attempts — a research program is steered less by its ambitions than by which of its instruments’ verdicts it trusts. As agentic systems start grading their own progress — and as labs increasingly automate capability evaluation — the graders become the load-bearing safety and progress infrastructure, and their failure modes inherit the asymmetry described here. A field that only polices inflated claims will converge on instruments that are excellent at refusing and unexamined at missing, and the capabilities it fails to see will not schedule a meeting to announce themselves. The disciplines in this essay are cheap relative to what they protect — clinical laboratories have run them daily, at scale, for forty years: a control battery is a few known cases run on every instrument change; a graveyard is a log file with a version stamp; source-swapping is one extra evaluation. What they buy is the right to trust your own “no” — which, for any system whose purpose is to become measurably less wrong over time, is the entire game.
Article 1 of a 4-part series on measurement and honest growth in AI systems; Articles 2 and 3 embody the doctrine this one states (negative controls; slope-not-count), and Article 4 extends it to the verification membrane — how systems and their evaluators train each other. All measurements referenced are reproducible from public data sources (reanalysis archives, national tide and weather services); per series policy, no proprietary datasets or internal statistics beyond sanitized ratios appear in this text, and the author’s own results are never reported on named benchmarks.