Contributions
- Verified memories are label factories [measured]. Units that passed an external verification gate yield leakage-clean training labels at near-zero annotation cost; a retriever trained this way shipped and is load-bearing in production.
- A policy-versus-generation boundary [measured, bounded]. In one system, on the same labels: policies that retrieve, rank and allocate paid; a small generator paid exactly zero. Stated as an observation with a known confound, not a law.
- The verification membrane [the frame this essay adds]. Parametric and non-parametric components are two sides of one system with symmetric failure modes when unverified data crosses — model collapse one way, a junk drawer the other — and a single gate defends both directions.
- Four ledger disciplines for memory [measured in the mirror system; proposed for LLM stacks]. Gate the door; deduplicate by behaviour; make memory revocable; measure the slope, not the count — each with the failure we measured when it was missing.
- Two pre-registered experiments [proposed]. Falsifiable designs, with predictions and disconfirmation conditions stated in advance, that would test the frame at LLM scale.
What was measured / what is proposed
Measured, in one running memory-first system: everything tagged [measured] above, the clawback audit, the behavioural-deduplication collapse, and the reuse-slope readings — including the unflattering current one. Proposed: every application to LLM stacks, and the two experiments at the end. Two of the four disciplines (deduplicate by behaviour; measure the slope) are measurement definitions and transfer to any system by construction.
1. The wrong debate
The argument is usually staged as a choice of architecture. One camp holds that intelligence lives in weights: scale the model, and external memory is a crutch that better parameters will absorb. The other holds that it lives in the library: compound knowledge outside the model, and gradient descent is a commodity you rent when needed. Both camps are arguing about where to put the knowledge. Neither is arguing about the thing that actually ran out.
What ran out is verification. A trillion tokens are easy; a trillion trustworthy tokens are not. A million banked skills are easy; a million skills that demonstrably work out-of-sample are not. Whatever side of the architecture debate you hold, your system's growth is rate-limited by the same scarce input: judgements, graded by reality rather than by the system itself, about what is true and what worked.
That is the thesis of this essay: verification — not architecture — is the scarce resource, and once you see it, the parametric-versus-non-parametric war dissolves into something more useful.
The field has already said half of this from the training side. Jason Wei crystallised it in 2025 as the verifier's law: "the ease of training AI to solve a task is proportional to how verifiable the task is." Reinforcement learning from verifiable rewards — the recipe behind Tulu 3 and DeepSeek-R1 — is that law applied at scale, and this essay takes it as a starting point, not a conclusion. What the consensus leaves on the table is the other half of the loop: verifier's law and RLVR spend verification at training time and discard it. Here, the verified corpus is a permanent, revocable, reusable object — and the same gate polices both crossings of one membrane. That difference is the subject of everything that follows.
The first three articles in this series were written from deep inside the library camp — the system we run keeps its knowledge in a ledger of externally verified units, not in weights. So this essay may look like a defection. It is not. It is a report on the traffic between the two camps, measured inside one running system. The picture that emerged is not a winner but a membrane: two sides of one organism, with data crossing in both directions — the ledger training the model side, the model side maintaining the ledger — and a verification gate policing every crossing. The two directions fail in the same way when unverified data crosses, and one mechanism defends both.
2. The mirror world: why these measurements exist
A fair question first: why should builders of LLM systems take memory advice from a system that has no LLM in it? Because that absence is exactly what makes the measurements exist.
In a typical LLM stack, the non-parametric components — the retrieval store, the skill library, the agent memory — are auxiliary. When the memory rots, a strong generator papers over it: retrieval quality degrades gracefully, junk entries are simply ignored, and the failure shows up, if at all, as a slow drift in downstream quality that gets attributed to something else. The pathologies are real but masked, so nobody measures them.
We built the mirror image. In our system the memory is the system: a library of units that each passed an external verification gate — out-of-sample, baseline-beating, leakage-checked — plus small policies that retrieve and compose over it. When that memory develops a pathology, nothing masks it; the system simply stops getting better. Its failure modes were fatal rather than hidden, which is why they got measured, diagnosed and fixed, and why the numbers in this essay exist at all.
Two things to hold from the start. First, the ruler: throughout this essay, the health of a memory is the slope of verified reuse — is verified reuse per query rising over time? — a measure introduced and defended in Article 3 of this series and imported here as the standard instrument. Second, the stakes: when admission to memory is ungated, the rot is not marginal. On audit, roughly seven in ten of everything our system had ever admitted turned out to be inflation. Section 6 shows that measurement in full; keep it in mind through Direction 1, because it is why the gate earns its keep.
3. Direction 1 — the ledger trains the model
Start with the direction almost nobody exploits. A library whose every entry passed an external verification gate has a property that training corpora almost never have: each unit arrives already graded by reality, already checked out-of-sample, already screened for leakage. Those are precisely the properties that make supervised data expensive. The ledger produces them as a side effect of existing.
(x, y) is a training pair <=> y passed the gate gate(y) <=> verified_external AND out_of_sample AND lift > 0 AND leakage_clean — F1 — only units reality graded become labels; annotation cost is approximately zero.
We trained small parametric components on this label factory three times, in three different roles. The outcomes disagree, and the disagreement is the finding.
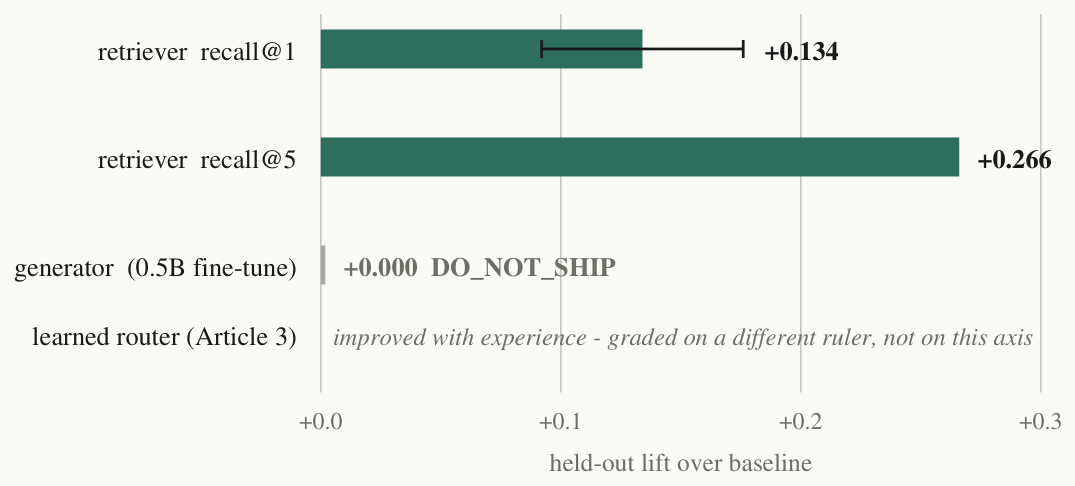
(a) The retriever worked. A small, owned, CPU-trained embedding model learned premise retrieval from the memory's own citation records — when a verified unit enters the ledger, the premises it genuinely used are recorded, and those records are ground-truth relevance labels by construction. Nobody annotated anything. On a held-out evaluation of several hundred goals against a token-overlap baseline it reached recall@1 of 0.286 against the baseline's 0.152 — a lift of +0.134 with a 95% confidence interval of [0.092, 0.176], clear of zero — and recall@5 of 0.578 against 0.312. On the much smaller frontier subset that production actually faces, its top suggestion was a verified load-bearing premise roughly nineteen times in twenty; that subset is small, so we report the figure as directional rather than definitive. And in the system's own component-value accounting, this retriever is currently the one component with verified load-bearing attribution (lift +0.255, with the lower bound of its interval at +0.170). Direction 1 is not a thought experiment; it is in production.
The label-factory idea has neighbours, and precision about them matters. V-STaR trains a verifier from a model's own correct and incorrect solutions; LRAT trains retrievers from records of what search agents actually used mid-trajectory. Both harvest supervision from system behaviour rather than from annotators. Neither couples the harvest to a gated, provenance-carrying corpus — the configuration in which every label arrives pre-cleaned for leakage and out-of-sample validity, and can be revoked later if the unit it came from falls.
(b) The generator failed — and the verdict shipped anyway, as a verdict. We fine-tuned a small (roughly half-billion-parameter) open-weight base model on the same verified substrate, hoping the label factory would buy generation the way it bought retrieval. On held-out problems graded by the external checker, the fine-tuned model solved exactly the fraction the base model solved: a handful of wins was bought with an equal handful of regressions, for a held-out lift of exactly zero. The recorded verdict is DO_NOT_SHIP. One confound should be stated in our own voice before a reviewer states it for us: the base model tends to emit an obsolete dialect of the target formal language, so part of the failure may be substrate mismatch rather than scale. We cannot separate the two at this size. The honest claim is exactly that bounded: at this scale, on this substrate, with that confound, generation returned nothing.
(c) The router compounded. In the compositional-reasoning domain of Article 3, the component that actually improved with experience was the ranking policy whose training signal was the system's own verified solve history — not the library of banked solutions, whose measured contribution stayed near zero. The competence allocator of Article 2 is the same shape a third time: statistics computed from verified outcomes, steering compute. We cross-reference rather than re-derive; both essays carry the numbers.
| Component | Training signal | Held-out result | Verdict |
|---|---|---|---|
| Retriever — small owned embedding model | citation records of verified units | recall@1 0.286 vs 0.152 baseline; CI clear of zero | shipped; load-bearing in production |
| Generator — small open-weight fine-tune | the verified units themselves | lift exactly zero; wins = regressions | DO_NOT_SHIP (recorded) |
| Router — ranking policy (Article 3) | the system's own verified solve history | improved with experience; library size alone did not | the compounding lever in its domain |
4. The boundary: policy versus generation
Look closely at the three winners and one framing dissolves. The retriever is a trained embedding model — parametric, gradient descent, the works. The router is a count-based ranking memory with no gradients in it at all. The allocator is arithmetic over verified outcomes. If the real boundary were parametric versus non-parametric, this trio should not exist. The line the evidence draws runs somewhere else: between policy and generation.
Policies make compact decisions over verified context: which premise to retrieve, which candidate to expand, which task deserves compute. Their supervision is cheap and dense — every verified unit labels the decisions that produced it — and their errors are recoverable: a bad retrieval wastes a search branch and nothing else. Generation produces the artifact itself. There the label "this unit is correct" turns out to be thin supervision — it says nothing about how the artifact was produced — and errors are terminal: a wrong artifact is simply rejected at the gate, teaching nothing. In our system, the same label factory that made a policy compound made a generator tread water.
State the boundary carefully, because it is an observation from one system, not a law. It was measured once, small, on one substrate, with a known confound. Larger generators trained on externally verified signals demonstrably work — that is what reinforcement learning from verifiable rewards is, and the field is scaling it now. What the mirror system adds is the asymmetry: at a scale where the retriever paid clearly and attributably, the generator paid nothing.
There is a second reason the zero does not argue with those results, and it is more interesting than scale: the gate sat in a different place. Our generator was fine-tuned on gate-passed data — verification ran once, before training, as a filter on the corpus. Reinforcement learning from verifiable rewards keeps the verifier inside the training loop: every attempt is graded, and the gradient itself carries the verdict. Same gate, different position. A filtered corpus teaches what verified output looks like; a verifier in the loop teaches what it takes to produce one. If the membrane frame is right that the border must be policed, the RLVR results sharpen it: for generation, the border may need to run through the training loop itself, not just through the dataset. That is a more precise hypothesis than "generation fails," and the first experiment in Section 8 gains a natural third arm from it. If one idea here survives contact with scale, we expect it to be this: do not ask whether your system has a verifier — ask where the verifier sits.
In one system, on the same labels: policies over verified memory compounded, and generation did not. The role made the difference — not the mechanism.
5. One system, two crossings
Put both directions on one diagram and the shape of the whole system appears: a loop through a gated border.
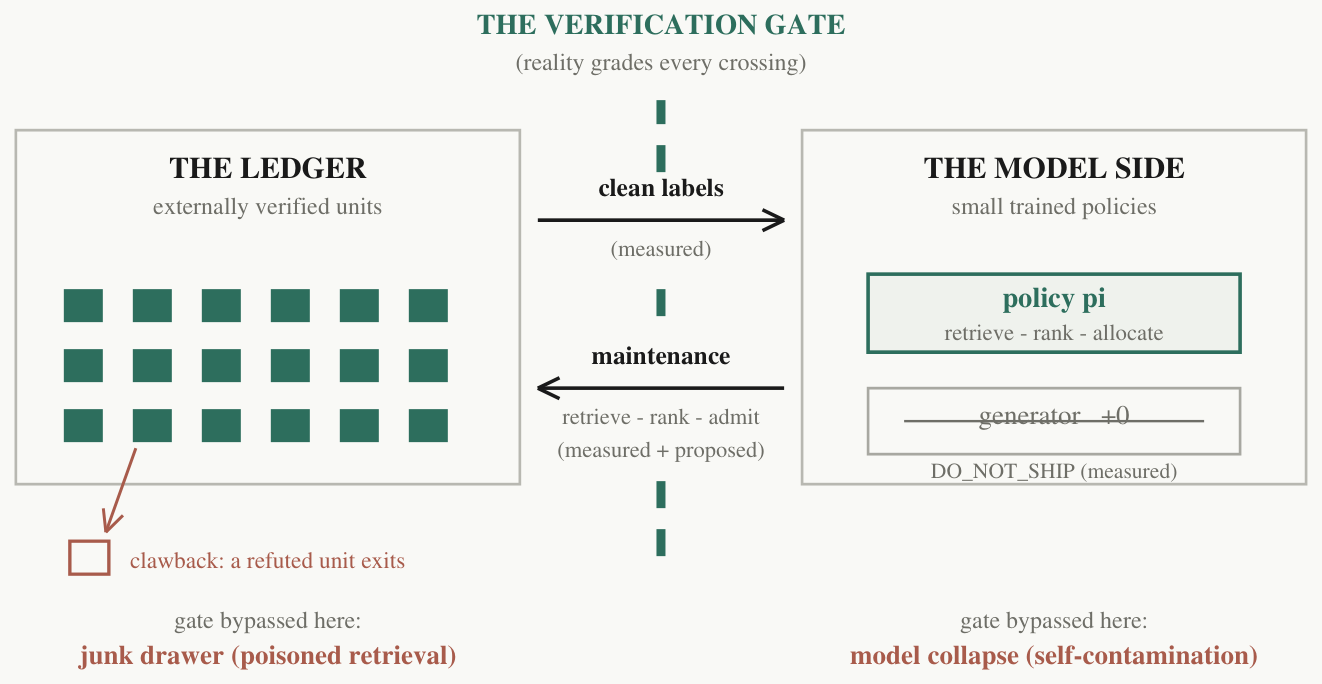
L_t --labels--> D_t --train--> pi_(t+1) [ledger -> model] pi_(t+1) --retrieve/rank/admit--> dL_verified [model -> ledger] L_(t+1) = gate(L_t + dL) [both crossings gated] — F2 — gradients touch only the small policy; knowledge accumulates only in the ledger; the gate sits on BOTH crossings.
Each side compensates for the other's structural weakness. A ledger cannot generalise — it knows only what was verified. A policy cannot be trusted — it interpolates, and interpolation lies. The gate moves trust across the membrane in one direction and generalisation across it in the other, and neither property survives the crossing without it.
A worked example: one unit's life across the membrane
- Proposed. Search produces a candidate regularity — a unit that might be true and might be useful. Nothing is claimed yet.
- Gated. The candidate must predict out-of-sample, beat the strongest available baseline, and pass a leakage check. Most candidates die here. This is the only doorway into the ledger.
- Banked, with provenance. The unit enters the ledger carrying its evidence and the identities of the prior units it genuinely used. Those citations are the crucial by-product.
- Harvested. The citation records are free training labels: query, useful premise, by construction. The retriever trains on them — no annotation, no leakage, because the gate already checked both.
- Compounded. The better retriever surfaces the unit for a later, harder problem; a new unit passes the gate citing it. The old unit is now load-bearing, and the reuse slope — the ruler from Article 3 — ticks up.
- Revocable, forever. If the unit is ever refuted, clawback removes it, and every unit citing it is re-examined. The corpus can un-learn. No frozen training set can.
6. Direction 2 — the model side maintains the ledger
Now reverse the arrow. Every LLM system already has non-parametric components: the retrieval store is one, the skill library is one, the agent memory is one, the tool registry is one. What most of them lack is not the component but the operating discipline — and we know specifically what breaks without it, because in the mirror world those breakages were fatal and had to be measured. The one-line version: stop treating memory as a cache and start treating it as a ledger.
cache: store(e) <=> looked_useful(e) ledger: store(e) <=> verified(e) — F3 — the difference is who grades the entry: the system's own impression, or reality.
L1. Gate the door. Problem: memories admit whatever looked useful, and every entry looks useful on the day it arrives. Observation: our admission pipeline once auto-admitted new material on pattern-match, and the store rotted in place — an independent audit found that what had presented as ten distinct sources of new knowledge collapsed to three real underlying engines, each alias inflating the metrics that justified admitting the next; across the store's whole history, roughly seven in ten of everything ever admitted was eventually revoked as inflation. Nobody cheated. Recommendation: admission requires external verification — an out-of-sample check against a real baseline — not a usefulness impression. If that sounds slow, note what the alternative bought us.
L2. Deduplicate by behaviour, not surface. Problem: stores are deduplicated by surface similarity and reported by count, so growth looks like capability. Observation: measured in Article 3, which owns these numbers: deduplicated by behaviour — same input-to-output mapping on a probe battery — only about seven percent of a large operation library was distinct, and roughly one entry in five was a strict no-op. The point this essay adds: embedding similarity would have caught almost none of it, because the duplicates had different names and different source code with identical behaviour. Recommendation: deduplicate by what an entry does, subtract the no-ops, and report that number as the honest size.
L3. Make memory revocable. Problem: a memory that cannot un-learn a bad entry poisons itself permanently. Observation: the L1 audit was only possible because revocation existed — you cannot measure a store's rot, let alone repair it, without the machinery to reverse an admission; every clawback also triggered re-examination of the entries that cited the revoked unit. Recommendation: track provenance from the first entry onward, and give the store a reverse gear. It is not free, and it is not optional.
L4. Measure the slope, not the count. Problem: documents stored, skills banked, entries admitted — all counts, all paddable, all inflated by exactly the pathologies above; Article 3 owns the full argument for why counts fail, and we import its conclusion. Recommendation: the health metric for a memory is whether verified reuse per query is rising over time, and nothing else. Our own current reading is below.
effective_size = |behaviourally distinct entries| - |no-ops| memory_health = d(verified reuse per query) / dt — F4 — deduplicate by behaviour, then report the slope, never the count.
And here is the discipline practised in public: as of this writing, our own memory-health gauge reads RED — the verified-reuse slope of the system this essay is built on is currently below its own threshold. The instrumentation did not certify compounding; it made the absence of compounding impossible to hide. We publish the reading because a health metric you only quote when it is green is a vanity metric.
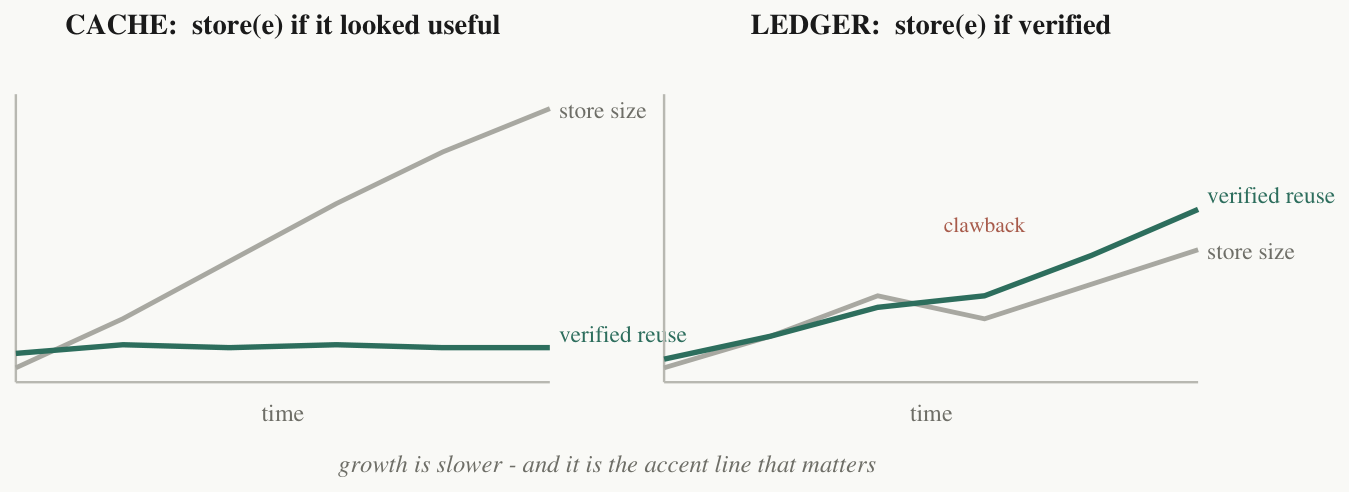
A growing store with flat reuse is a junk drawer, not a brain.
A note on timing, because it changes what kind of claim this is. Each of these disciplines now has a contemporaneous paper of its own. Admission control for agent memory has one (A-MAC). Tool libraries governed by typed and behavioural specifications have one (CoCoDA). Revocation that reaches both parameters and memory has one (Agentic Unlearning); memory-lifecycle governance has one (SSGM); and the security literature now motivates the gate from the threat side, showing that a handful of poisoned experiences implanted in an agent's memory can persistently compromise it (MemoryGraft). On the training-side crossing, verifier-guided retraining is being formalised as the escape from model collapse — with an honest caveat worth carrying: an imperfect verifier buys near-term gains and long-run convergence to the verifier's own knowledge, not a free lunch. The field is converging on the parts, piecewise. What has no paper, to our knowledge, is the symmetry — that these are one pathology with two addresses, and that a single gate, with correction channels in both directions, defends both. That is the claim this essay exists to make.
7. The symmetry: two failure modes, one gate
Here is the merge that makes the two halves of this essay one argument. Run data across the membrane ungated, in either direction, and the system starts grading its own homework at the border — and the same structural failure appears wearing two different names.
Ungated store-to-model: the system trains on its own unverified outputs. The literature calls this model collapse or self-training contamination — distributions narrow, errors compound, and the model drifts toward its own artifacts. Ungated model-to-store: the memory fills with self-judged "successes." The store swells, retrieval is progressively poisoned, and you get the junk drawer of L1 — our measured seven in ten. Two communities study these as separate pathologies. They are one pathology with two addresses.
ungated store -> model => self-contamination (model collapse) ungated model -> store => junk drawer (poisoned retrieval) defence for BOTH = the verification gate at the membrane — F5 — one border, policed in both directions.
The gate also admits one small derivation, offered in place of a slogan. If the gate's false-positive rate is epsilon — the fraction of bad units it wrongly admits — then contamination entering per crossing is bounded by epsilon in both directions, because both flows pass the same gate. The quality of the whole membrane is one number, and it can be estimated from either side: audit the store, or audit the training corpus, and you are measuring the same epsilon.
The symmetry extends to the correction machinery. Clawback (Direction 2) un-admits a false positive; re-grading the rejection graveyard re-admits a false negative — same operation, opposite directions, and both have run in our system (Article 1 tells the graveyard story in full). The shape of the result is the part worth restating: a working re-admission channel mostly confirms — one that recovered everything would mean the gate had been broken all along.
Nothing crosses the border, in either direction, unless reality graded it.
Where does this sit against the field? A process reward model scores steps; a gate admits units to a corpus that outlives any single training run. In retrieval-augmented generation and its descendants, the memory augments a generator; here the two sides supervise and maintain each other. Toolformer-style self-supervision is the label-factory idea aimed at tool use — the model labels its own calls by whether they seemed to help; the ledger version demands that the grading be external. And the skill libraries of open-ended agents and wake-sleep program learners are exactly the in-the-wild components the four disciplines of Section 6 apply to. Table 2 compresses the comparison.
| Approach | Who grades admission? | Memory revocable? | Gated crossings | What accumulates |
|---|---|---|---|---|
| Naive self-training | the model itself | no | none | weights (contaminated) |
| RAG store (typical practice) | "looked useful" heuristics | rarely | none | documents (unaudited) |
| Process reward models | a trained verifier, per step | n/a (scores, not a corpus) | model-side only | weights |
| RLVR | an external checker | no (reward is consumed, not stored) | store-to-model only | weights |
| Ledger membrane (this essay) | an external gate, both directions | yes — clawback + graveyard re-grade | both | verified units + a small policy |
8. Two experiments anyone can run
Proposal, not result
Nothing in this section has been run at LLM scale, by us or (to our knowledge) by anyone. The mirror system is an existence proof of the loop at small scale, nothing more. These are the two falsifiable experiments the frame stakes itself on; either could kill it.
Agent A: fine-tune on self-judged successes Agent B: fine-tune ONLY on ledger-verified episodes compare: held-out generality, reward-hacking incidence, calibration — F6 — prediction: B sees less data and generalises better per example; if A also wins held-out, Direction 1 is wrong at scale.
F6 is the training-side test. Both agents run the same tasks with the same budget; they differ only in who grades an episode before it becomes training data — the agent's own judgement, or an external verifier with an out-of-sample check. The gate-position observation of Section 4 supplies a natural third arm: an agent trained with the verifier inside the loop rather than as a corpus filter, to separate what the gate's position buys from what its existence buys. The interesting outcome is not whether B's corpus is smaller (it will be) but whether B's per-example transfer to held-out task families is higher, and whether A's reward-hacking incidence is measurably worse. Paired comparisons with bootstrap intervals are the minimum standard here; differences of a few points are exactly the effect sizes that vanish without error bars.
Agent C: cache memory (append-on-useful, similarity dedup, no revocation) Agent L: ledger memory (F3-gated, behaviour-deduped, revocable) compare over time: F4 slope, held-out lift, junk fraction on audit — F7 — prediction: L grows slower, reuses more, and its lift compounds; if C's reuse slope matches L's, Direction 2 is wrong.
F7 is the memory-side test, and it is cheap: the same agent framework, two memory implementations, identical task streams. Audit both stores at fixed intervals with the L2 protocol — behavioural deduplication needs an executable notion of behaviour, which is the honest difficulty for free-text memories; embedding similarity is the available approximation and should be reported as such. Our prediction is stated above, in public, before the experiment; that is the discipline this series keeps asking the field to adopt, applied to ourselves.
Runnable scaffolds for both designs will be published in the series' companion repository (github.com/MC-MatthewChilds/honest-measurement); anyone who runs either experiment — with either outcome — is invited to write matthew.childs@myyahoo.com.
Glossary
Verification gate — the external check a unit must pass to cross the membrane: out-of-sample, baseline-beating, leakage-clean. Ledger — a memory whose every entry passed the gate, with provenance. Cache — a memory admitting whatever looked useful. Load-bearing — a stored unit that a later verified unit genuinely depended on. Clawback — revoking an admitted unit that was later refuted, and re-examining its citers. Graveyard re-grade — re-testing rejected candidates when the instrument improves (Article 1). Reuse slope — the change over time in verified reuse per query; the health metric for any memory (Article 3).
Limitations
The empirical core is small-scale and one substrate. Every measured number in this essay comes from one running system built by one small team. The retriever's frontier subset in particular is small enough that we label its figure directional. We have argued a pattern, not established a law.
The generator's zero has a confound. The base model emits an obsolete dialect of the target formal language, so its failure conflates scale with substrate mismatch. A clean replication would use a base model native to the target language. Until then, the policy-versus-generation boundary is a measured observation with an asterisk we attached ourselves.
Our own reuse slope currently reads RED. The disciplines of Direction 2 do not guarantee compounding; they make its absence visible. Ours is visible right now. If the slope has not recovered by the time this series continues, that is the next essay's problem to report, not to bury.
No LLM-stack A/B has been run. Everything LLM-facing here is proposal, and F6/F7 name the experiments that would settle it. The disciplines also have costs we do not minimise: gates slow accumulation; behavioural deduplication is genuinely hard for free-text memories; clawback requires provenance from day one.
The boundary from Article 3 still applies. In domains with deep multi-step reuse, the library side matters more and the balance of the membrane shifts. The lesson is "measure which side is compounding before scaling either" — not "libraries are useless" and not "generators are useless."
Why it matters
The field is converging on verification from the training side: reinforcement learning from verifiable rewards is the gate, arrived at independently and at scale. But the reward is consumed at training time and discarded, while on the other side of the same systems, agent memories and retrieval stores grow ungated — graded by the system's own impression of usefulness, deduplicated by surface, irrevocable, and reported as counts. That is the same mistake the training side just spent years correcting, made in the opposite direction. The claim of this essay is that both sides are one problem: verification is the scarce resource, the membrane is where it is spent, and its quality is one measurable number with correction channels in both directions. We ran the memory-first half of that loop far enough to watch it fail in every way described here, and to measure the repairs. The honest object is a slope you own and reality grades — not a threshold someone else scores. And the principle underneath the whole essay fits in one line: reality — not the model — decides what becomes permanent knowledge.